Binary search
Binary search is the term used in computer science for the discrete version of the bisection method, in which given a monotone function 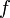 over a discrete interval
over a discrete interval 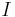 and a target value
and a target value 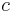 one wishes to find
one wishes to find 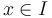 for which
for which 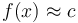 . It is most often used to locate a value in a sorted array. The term may also be used for the continuous version.
. It is most often used to locate a value in a sorted array. The term may also be used for the continuous version.
Contents
Informal introduction: the guessing game
In the number guessing game, there are two players, Alice and Bob. Alice announces that she has thought of an integer between 1 and 100 (inclusive), and challenges Bob to guess it. Bob may guess any number from 1 to 100, and Alice will tell him whether his guess is correct; if it is not correct, she will tell him (truthfully) either that her number is higher than his guess, or that it is lower.
One possible strategy that Bob can employ that guarantees he will eventually win is simply guessing every integer from 1 to 100 in turn. First Bob says "1" and (for example) Alice replies "Higher". Then Bob says "2" and again Alice replies "Higher", and so on. Eventually Bob says "40" and Alice says "Correct", and the game is over. While this strategy is simple and correct, it may require up to 100 guesses to finish the game.
However, there is a much cleverer strategy. Initially, Bob knows the number lies somewhere between 1 and 100. He guesses a number close to the middle of this range; say, 50. Alice replies, "Lower". Now Bob knows the number lies in the range 1 to 49, so again he picks a number close to the middle of the range, say, 25. Alice replies, "Higher", and the range has now been narrowed to 26 to 49. In this way, in every step, Bob will narrow the range to half its previous size. Eventually, either Bob will guess the number correctly, or there will only be one number left in the range, which must be Alice's number. Furthermore, this strategy will take at most 7 steps, because 100 halved 7 times is less than one. In general, the number of steps it takes Bob to find an integer between 1 and 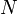 is at most about
is at most about 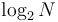 , whereas the naive "linear search" strategy introduced earlier may require up to steps. We see that the bisection strategy, or binary search, is a vast improvement over the linear search.
, whereas the naive "linear search" strategy introduced earlier may require up to steps. We see that the bisection strategy, or binary search, is a vast improvement over the linear search.
Furthermore, binary search is the best possible strategy at Bob's disposal. This is because Bob asks a series of questions and gets a reply of "Higher" or "Lower" to each one except the last (which is always "Correct"), and based on this information alone must determine the number; so the total number of possible answers that Bob can determine is at most the number of such sequences, which is approximately 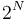 if the length is limited to questions; so no strategy that asks less than questions can guarantee being able to guess all possible answers.
if the length is limited to questions; so no strategy that asks less than questions can guarantee being able to guess all possible answers.
Finding an element in an array
In the most commonly encountered variation of binary search, we are given a zero-indexed array 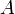 of size
of size 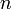 that is sorted in ascending order, along with some value . There are two slightly different variations on what we wish to do:
that is sorted in ascending order, along with some value . There are two slightly different variations on what we wish to do:
- Lower bound: Here are two equivalent formulations:
- Find the first index into where we could insert a new element of value without violating the ascending order.
- If there is an element in with value greater than or equal to , return the index of the first such element; otherwise, return . In other words, return
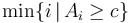 , or if that set is empty.
, or if that set is empty.
- Find the first index into
- Upper bound:
- Find the last index into where we could insert a new element of value without violating the ascending order.
- If there is an element in with value strictly greater than to , return the index of the first such element; otherwise, return . In other words, return
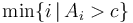 , or if that set is empty.
, or if that set is empty.
- Find the last index into
The following properties then hold:
- If there is no
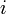 such that
such that 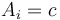 , then the lower bound and upper bound will be the same; they will both point to the first element in that is greater than .
, then the lower bound and upper bound will be the same; they will both point to the first element in that is greater than .
- If is larger than all elements in , then the lower and upper bounds will both be .
- If
- If there is at least one element with value , then the lower bound will be the index of the first such element, and the upper bound will be the index of the element just after the last such element. Hence [lower bound, upper bound) is a half-open interval that represents the range of indices into that refer to elements with value .
- The element immediately preceding the lower bound is the last element with value less than , if this exists, or the hypothetical element at index -1, otherwise.
- The element immediately preceding the upper bound is the last element with value less than or equal to , if this exists, or the hypothetical element at index -1, otherwise.
Of course, sometimes you only care whether the exact value you are seeking can be found in the array at all; but this is just a special case of lower bound.
Both lower bound and upper bound can easily be found by iterating through the array from beginning to end, which takes 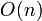 comparisons and hence time if the elements of the array are simple scalar variables that take
comparisons and hence time if the elements of the array are simple scalar variables that take 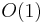 time to compare. However, because the array is sorted, we can do better than this. We begin with the knowledge that the element we seek might be anywhere in the array, or it could be "just past the end". Now, examine an element near the centre of the array. If this is less than the element we seek, we know the element we seek must be in the second half of the array. If it is greater, we know the element we seek must be in the first half. Thus, by making one comparison, we cut the range under consideration into half. It follows that after
time to compare. However, because the array is sorted, we can do better than this. We begin with the knowledge that the element we seek might be anywhere in the array, or it could be "just past the end". Now, examine an element near the centre of the array. If this is less than the element we seek, we know the element we seek must be in the second half of the array. If it is greater, we know the element we seek must be in the first half. Thus, by making one comparison, we cut the range under consideration into half. It follows that after 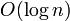 comparisons, we will be able to locate either the upper bound or the lower bound as we desire.
comparisons, we will be able to locate either the upper bound or the lower bound as we desire.
Implementation
However, implementation tends to be tricky, and even experienced programmers can introduce bugs when writing binary search. Correct reference implementations are given below in C:
/* n is the size of the int[] array A. */ int lower_bound(int A[], int n, int c) { int l = 0; int r = n; while (l < r) { int m = (l+r)/2; /* Rounds toward zero. */ if (A[m] < c) l = m+1; else r = m; } return l; } int upper_bound(int A[], int n, int c) { int l = 0; int r = n; while (l < r) { int m = (l+r)/2; if (A[m] <= c) /* Note use of < instead of <=. */ l = m+1; else r = m; } return l; }
Proof of correctness
We prove that lower_bound above is correct. The proof for upper_bound is very similar.
We claim the invariant that, immediately before and after each iteration of the while loop:
- The index we are seeking is at least
l. - The index we are seeking is at most
r.
This is certainly true immediately before the first iteration of the loop, where l = 0 and r = n. Now we claim that if it is true before a given iteration of the loop, it will be true after that iteration, which, by induction, implies our claim. First, the value m will be exactly the arithmetic mean of l and r, if their sum is even, or it will be 0.5 less than the mean, if their sum is odd, since m is computed as the arithmetic mean rounded down. This implies that, in any given iteration of the loop, m's initial value will be at least l, and strictly less than r. Now:
- Case 1:
A[m] < c. This means that no element with index betweenlandm, inclusive, can be greater thanc, because the array is sorted. But because we know that such an element exists (or that it is the hypothetical element just past the end of the array) in the current range delineated by indiceslandr, we conclude that it must be in the second half of the range with indices fromm+1tor, inclusive. In this case we setl = m+1and at the end of the loop the invariant is again satisfied. This is guaranteed to increase the value ofl, sincemstarts out with value at leastl. It also does not increaselbeyondr, sincemis initially strictly less thanm. - Case 2:
A[m] >= c. This means that there exists an element with index betweenlandm, inclusive, which is at leastc. This implies that the first such element is somewhere in this half of the range, because the array is sorted. Therefore, after settingr = m, the range of indices betweenlandr, inclusive, will still contain the index we are seeking, and hence the invariant is again satisfied. This is guaranteed to decrease the value ofr, sincemstarts out strictly less thanr; it also will not decrease it beyondl, sincemstarts out at least as large asl.
Since each iteration of the loop either increases l or decreases r, the loop will eventually terminate with l = r. Since the invariant still holds, this unique common value must be the solution. 
Carefully proving the time bound and showing the correctness of upper_bound are left as exercises to the reader.
Possible bugs
As suggested below, the programmer has at least six opportunities to err.
- Setting
r = n-1initially. Doing this will prevent the valuenfrom ever being returned, which renders the implementation correct whenever the answer is less thann, but incorrect whenever it isn. (It will simply returnn-1in this case.) - Using
while (l <= r)instead ofwhile (l < r). This will always cause an infinite loop in which theelsebranch is taken in every subsequent iteration. - Comparing
A[m]withcin the wrong direction, that is, writingA[m] > c,A[m] >= c,c < A[m], orc <= A[m], or reversing the order of the two branches. This would not correspond to the theory, and would almost always given an incorrect result. Note that simultaneously logically negating the comparison and reversing the order of the branches, however, will not give an error, but will instead give logically equivalent code. - Computing
mas the ceiling of the arithmetic mean, instead of the floor. The obvious error condition here is that whenl == n-1andr == n, the value ofmcomputed will ben, and we will then attempt to examine a nonexistent element in the array, which could cause the program to crash. - Setting
l = morl = m-1instead ofl = m+1. Either variation lends itself to an error condition in whichmcomes out to be equal to eitherlorl+1, respectively, and the first branch is taken, which causes an infinite loop in which the first branch is always taken. - Setting
r = m+1orr = m-1instead ofr = m. In the former case, we could have an infinite loop in which the second branch is always taken, if the difference betweenlandris 1 or 2. In the latter case, it is possible forrto become less thanl.
And, of course, one can easily mix up the upper_bound and lower_bound implementations, giving a seventh opportunity to err.
Additionally, if the array can be very large, then m should be computed as l + (r-l)/2, instead of (l+r)/2, in order to avoid possible arithmetic overflow.
Inverse function computation
Both the number guessing game and the array search can be expressed as specific cases of the more general problem of discrete inverse function computation, hinted at in the lead section of this article.
We suppose:
- We are given some (straightforward to compute) function from a discrete totally ordered domain (such as the integers from the interval
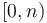 ) to any totally ordered codomain (such as the real numbers);
) to any totally ordered codomain (such as the real numbers); - is a monotonically increasing function, so that
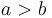 implies
implies 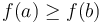 ;
; - We are given some value in 's codomain. (On the other hand, may or may not be in 's range.)
Here,
- The lower bound is the smallest argument
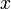 such that
such that 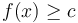 , if any exists.
, if any exists. - The upper bound is the smallest argument such that
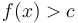 , if any exists.
, if any exists.
Sometimes there is exactly one such that 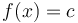 . This value can properly be denoted
. This value can properly be denoted 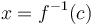 ; finding the value is computing the inverse of at . Other times, there will be multiple such values, or there will only be such that ; in any case, binary search will find these values for us.
; finding the value is computing the inverse of at . Other times, there will be multiple such values, or there will only be such that ; in any case, binary search will find these values for us.
The approach mirrors that of the previous two sections. Initially we only know that lies somewhere in the domain of , so we guess a value that roughly splits this range in half; by evaluating at this point and comparing the result with , we can discard half the range and repeat as many times as necessary (about 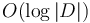 times, where
times, where 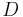 is the domain).
is the domain).
The number guessing game is a special case of this version of the problem. One possible way to formulate it is that 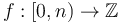 is defined as
is defined as 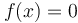 for some (the secret number),
for some (the secret number), 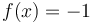 for all smaller numbers, and
for all smaller numbers, and 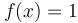 for all larger numbers; finding the secret number is just a matter of doing a binary search on
for all larger numbers; finding the secret number is just a matter of doing a binary search on 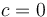 .
.
The array search problem is also a special case. Here we simply define 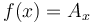 . In fact, the two problems are in some sense equivalent, in that a function with a discrete totally ordered domain is isomorphic to an array; the distinction will be lost in any programming language that implements both lazy evaluation and memoization.
. In fact, the two problems are in some sense equivalent, in that a function with a discrete totally ordered domain is isomorphic to an array; the distinction will be lost in any programming language that implements both lazy evaluation and memoization.
More generally, binary search is often very useful for problems that read something like "find the maximum such that 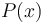 ". For example, in Trucking Troubles, the problem essentially down to finding the maximum such that the edges of the given graph of weight at least span the graph. This problem can be solved using Prim's algorithm to construct the "maximum spanning tree" (really, the minimum spanning tree using negated edge weights), but binary search provides a simpler approach. We know that is somewhere in between the smallest edge weight in the graph and the largest edge weight in the graph, so we start by guessing a value roughly halfway in-between. Then we use depth-first search to test whether the graph is connected using only the edges of weight greater than or equal to our guess value. If it is, then the true value of is greater than or equal to our guess; if not, then it is less. This is then repeated as many times as necessary to determine the correct value of .
". For example, in Trucking Troubles, the problem essentially down to finding the maximum such that the edges of the given graph of weight at least span the graph. This problem can be solved using Prim's algorithm to construct the "maximum spanning tree" (really, the minimum spanning tree using negated edge weights), but binary search provides a simpler approach. We know that is somewhere in between the smallest edge weight in the graph and the largest edge weight in the graph, so we start by guessing a value roughly halfway in-between. Then we use depth-first search to test whether the graph is connected using only the edges of weight greater than or equal to our guess value. If it is, then the true value of is greater than or equal to our guess; if not, then it is less. This is then repeated as many times as necessary to determine the correct value of .
Continuous
TODO
Problems
For some of these problems, binary search might not yield an optimal solution, or even get all the points; but the solution it gives far outperforms the naive algorithm.