Difference between revisions of "Binary search"
(Created page with "'''Binary search''' is the term used in computer science for the discrete version of the ''bisection method'', in which given a monotone function <math>f</math> over a discrete i...") |
m (→Possible bugs) |
||
| Line 74: | Line 74: | ||
However, there are still four degrees of freedom in the implementation: | However, there are still four degrees of freedom in the implementation: | ||
| − | |||
# Should we compute <code>m</code> as the floor of the arithmetic mean of <code>l</code> and <code>r</code>, or as the ceiling? | # Should we compute <code>m</code> as the floor of the arithmetic mean of <code>l</code> and <code>r</code>, or as the ceiling? | ||
| + | # Should we compare <code>A[m]</code> with <code>c</code> strictly, that is, with <code><</code>, or non-strictly, that is, with <code><=</code>? | ||
# Should we set <code>l = m+1</code>, <code>l = m</code>, or <code>l = m-1</code> in the first branch? | # Should we set <code>l = m+1</code>, <code>l = m</code>, or <code>l = m-1</code> in the first branch? | ||
# Should we set <code>r = m+1</code>, <code>r = m</code>, or <code>r = m-1</code> in the second branch? | # Should we set <code>r = m+1</code>, <code>r = m</code>, or <code>r = m-1</code> in the second branch? | ||
These variations are covered in the page [[Binary search/Implementation details]]. | These variations are covered in the page [[Binary search/Implementation details]]. | ||
Revision as of 08:14, 1 January 2012
Binary search is the term used in computer science for the discrete version of the bisection method, in which given a monotone function 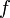 over a discrete interval
over a discrete interval 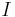 and a target value
and a target value 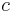 one wishes to find
one wishes to find 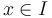 for which
for which 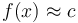 . It is most often used to locate a value in a sorted array. The term may also be used for the continuous version.
. It is most often used to locate a value in a sorted array. The term may also be used for the continuous version.
Discrete: array
In the most commonly encountered variation of binary search, we are given a zero-indexed array 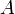 of size
of size 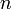 that is sorted in ascending order, along with some value . Here the domain of the function is the set of indices into the array, and
that is sorted in ascending order, along with some value . Here the domain of the function is the set of indices into the array, and 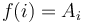 where
where 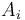 is the element at the
is the element at the 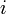 th position. There are two slightly different variations on what we wish to do:
th position. There are two slightly different variations on what we wish to do:
- Lower bound: Here are two equivalent formulations:
- Find the first index into where we could insert a new element of value without violating the ascending order.
- If there is an element in with value greater than or equal to , return the index of the first such element; otherwise, return . In other words, return
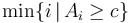 , or if that set is empty.
, or if that set is empty.
- Find the first index into
- Upper bound:
- Find the last index into where we could insert a new element of value without violating the ascending order.
- If there is an element in with value strictly greater than to , return the index of the first such element; otherwise, return . In other words, return
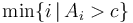 , or if that set is empty.
, or if that set is empty.
- Find the last index into
The following properties then hold:
- If there is no such that
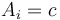 , then the lower bound and upper bound will be the same; they will both point to the first element in that is greater than .
, then the lower bound and upper bound will be the same; they will both point to the first element in that is greater than .
- If is larger than all elements in , then the lower and upper bounds will both be .
- If
- If there is at least one element with value , then the lower bound will be the index of the first such element, and the upper bound will be the index of the element just after the last such element. Hence [lower bound, upper bound) is a half-open interval that represents the range of indices into that refer to elements with value .
- The element immediately preceding the lower bound is the last element with value less than , if this exists, or the hypothetical element at index -1, otherwise.
- The element immediately preceding the upper bound is the last element with value less than or equal to , if this exists, or the hypothetical element at index -1, otherwise.
Both lower bound and upper bound can easily be found by iterating through the array from beginning to end, which takes 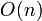 comparisons and hence time if the elements of the array are simple scalar variables that take
comparisons and hence time if the elements of the array are simple scalar variables that take 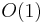 time to compare. However, because the array is sorted, we can do better than this. We begin with the knowledge that the element we seek might be anywhere in the array, or it could be "just past the end". Now, examine an element near the centre of the array. If this is less than the element we seek, we know the element we seek must be in the second half of the array. If it is greater, we know the element we seek must be in the first half. Thus, by making one comparison, we cut the range under consideration into half. It follows that after
time to compare. However, because the array is sorted, we can do better than this. We begin with the knowledge that the element we seek might be anywhere in the array, or it could be "just past the end". Now, examine an element near the centre of the array. If this is less than the element we seek, we know the element we seek must be in the second half of the array. If it is greater, we know the element we seek must be in the first half. Thus, by making one comparison, we cut the range under consideration into half. It follows that after 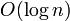 comparisons, we will be able to locate either the upper bound or the lower bound as we desire.
comparisons, we will be able to locate either the upper bound or the lower bound as we desire.
Implementation
However, implementation tends to be tricky, and even experienced programmers can introduce bugs when writing binary search. Correct reference implementations are given below in C:
/* n is the size of the int[] array A. */ int lower_bound(int A[], int n, int c) { int l = 0; int r = n; while (l < r) { int m = (l+r)/2; /* Rounds toward zero. */ if (A[m] < c) l = m+1; else r = m; } return l; } int upper_bound(int A[], int n, int c) { int l = 0; int r = n; while (l < r) { int m = (l+r)/2; if (A[m] <= c) /* Note use of < instead of <=. */ l = m+1; else r = m; } return l; }
Proof of correctness
We prove that lower_bound above is correct. The proof for upper_bound is very similar.
We claim the invariant that, immediately before and after each iteration of the while loop:
- The index we are seeking is at least
l. - The index we are seeking is at most
r.
This is certainly true immediately before the first iteration of the loop, where l = 0 and r = n. Now we claim that if it is true before a given iteration of the loop, it will be true after that iteration, which, by induction, implies our claim. First, the value m will be exactly the arithmetic mean of l and r, if their sum is even, or it will be 0.5 less than the mean, if their sum is odd, since m is computed as the arithmetic mean rounded down. This implies that, in any given iteration of the loop, m's initial value will be at least l, and strictly less than r. Now:
- Case 1:
A[m] < c. This means that no element with index betweenlandm, inclusive, can be greater thanc, because the array is sorted. But because we know that such an element exists (or that it is the hypothetical element just past the end of the array) in the current range delineated by indiceslandr, we conclude that it must be in the second half of the range with indices fromm+1tor, inclusive. In this case we setl = m+1and at the end of the loop the invariant is again satisfied. This is guaranteed to increase the value ofl, sincemstarts out with value at leastl. It also does not increaselbeyondr, sincemis initially strictly less thanm. - Case 2:
A[m] >= c. This means that there exists an element with index betweenlandm, inclusive, which is at leastc. This implies that the first such element is somewhere in this half of the range, because the array is sorted. Therefore, after settingr = m, the range of indices betweenlandr, inclusive, will still contain the index we are seeking, and hence the invariant is again satisfied. This is guaranteed to decrease the value ofr, sincemstarts out strictly less thanr; it also will not decrease it beyondl, sincemstarts out at least as large asl.
Since each iteration of the loop either increases l or decreases r, the loop will eventually terminate with l = r. Since the invariant still holds, this unique common value must be the solution. 
Carefully proving the time bound and showing the correctness of upper_bound are left as exercises to the reader.
Possible bugs
One obvious bug is absentmindedly setting r = n-1 initially. Doing this will prevent the value n from ever being returned, which renders the implementation correct whenever the answer is less than n, but incorrect whenever it is n. (It will simply return n-1 in this case.)
Another obvious bug is using while (l <= r) instead of while (l < r). This will always cause an infinite loop in which the else branch is taken in every subsequent iteration.
A third obvious bug is either comparing A[m] with c in the wrong direction, that is, writing A[m] > c, A[m] >= c, c < A[m], or c <= A[m], or reversing the order of the two branches. This would not correspond to the theory, and would almost always given an incorrect result.
However, there are still four degrees of freedom in the implementation:
- Should we compute
mas the floor of the arithmetic mean oflandr, or as the ceiling? - Should we compare
A[m]withcstrictly, that is, with<, or non-strictly, that is, with<=? - Should we set
l = m+1,l = m, orl = m-1in the first branch? - Should we set
r = m+1,r = m, orr = m-1in the second branch?
These variations are covered in the page Binary search/Implementation details.