Breadth-first search
Breadth-first search (BFS) is the type of graph search that arises when the oldest vertex on the fringe is always the first to leave it. Though its uses are not as widespread as those of DFS, its specific application to the problem of finding shortest paths in unweighted graphs provides an example of a model algorithm: an algorithm which solves one particular, precisely specified (yet important) problem, solves it well (in minimal time and space), and is easy to understand and to implement.
Contents
Principles
The name breadth-first search reflects the fact that BFS attempts to "spread out" from the source vertex as much as possible. After the source vertex is visited, all of its neighbours are added to the fringe. Since they have been added at this early stage, any future vertices added to the fringe will not be visited until after all of the source vertex's immediate neighbours. As each of these immediate neighbours is visited, its immediate neighbours are added too, but it is not until all the immediate neighbours of the source vertex have been visited that these newly added vertices are visited. Now we know that all of these newly added vertices of distance 2 from the source will be visited before any more distant vertices. So BFS visits all the vertices with distance 1 from the source, then all the vertices with distance 2 from the source, and so on; it appears to "radiate" out from the source vertex. As an example, consider the graph ({1,2,3,4,5,6,7},{(1,2),(1,3),(2,4),(2,5),(3,6),(3,7)}). Suppose the source vertex is 1. After it is visited, 2 and 3 are added to the fringe. If 2 is visited next, then 4 and 5 will be added to the fringe, but before either of these can be visited, it is 3's turn, since it was in the fringe earlier. So 3 is visited next, with 6 and 7 being added to the fringe. Now, however, 6 and 7 must wait for 4 and 5 to be visited, since they arrived in the fringe earlier. Evidently, BFS has a great tendency to "jump around"; for this particular graph, for example, visiting all the vertices in numerical order is a possible ordering for a BFS starting from vertex 1.
Implementation
The basic template given at Graph search can be easily adapted for BFS:
input G
for all u ∈ V(G)
let visited[u] = false
let Q be empty
let r be a node of depth zero
push(Q,r)
while Q is not empty
v = pop(Q)
if visited[v] = false
visit v
visited[v] = true
for each w ∈ V(G) such that (v,w) ∈ E(G) and visited[w] = false
push(Q,w)
F has been replaced by a queue, Q, because a queue satisfies exactly the necessary property for BFS: the most recently added item is the last to be removed.
Performance characteristics
Time
Most BFS algorithms feature a constant time "visit" operation. Suppose, for the sake of simplicity, that the entire graph consists of one connected component. Each vertex will be visited exactly once, with each visit being a constant-time operation, so 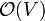 time is spent visiting vertices. Whenever a vertex is visited, every edge radiating from that vertex is considered, with constant time spent on each edge. It follows that every edge in the graph will be considered exactly twice — once for each vertex upon which it is incident. Thus, the time spent considering edges is again a constant factor times the number of edges,
time is spent visiting vertices. Whenever a vertex is visited, every edge radiating from that vertex is considered, with constant time spent on each edge. It follows that every edge in the graph will be considered exactly twice — once for each vertex upon which it is incident. Thus, the time spent considering edges is again a constant factor times the number of edges, 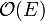 . This makes BFS
. This makes BFS 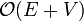 overall, linear time, which, like DFS, is asymptotically optimal for a graph search.
overall, linear time, which, like DFS, is asymptotically optimal for a graph search.
(The foregoing analysis is not rigorous, because it is possible to have multiple copies of a vertex on the queue at any given time. However, we can easily fix this by adding a boolean array to prevent pushing a vertex onto the queue multiple times, and even if we don't, a more detailed analysis shows that the time used is still linear.)
Space
There can be no more than vertices on the queue at any given time, because every addition of a vertex to the stack is due to the traversal of an edge (except for that of the initial vertex) and no edge can be traversed more than twice. The space required by the queue is therefore bounded by . space is also required to store the list of visited vertices, so space is required overall.
Applications
BFS, by virtue of being a subcategory of graph search, is able to find connected components, paths (including augmenting paths), spanning trees, and topological orderings in linear time. In addition, BFS is the algorithm of choice for finding shortest paths in unweighted graphs.
The following example shows how to find connected components and a spanning forest (a collection of spanning trees, one for each connected component) with BFS.
input G
let cnt = 0
for all u ∈ V(G)
let id[u] = -1
for each u ∈ V(G)
if id[u] = -1
let Q be empty
push(Q,(u,u))
while Q is not empty
(u,v) = pop(Q)
if id[v] = -1
id[v] = cnt
let pred[v] = u
for each w ∈ V(G) such that (v,w) ∈ E(G)
push(Q,(v,w))
cnt = cnt + 1
After the termination of this algorithm, cnt will contain the total number of connected components, id[u] will contain an ID number indicating the connected component to which vertex u belongs (an integer in the range [0,cnt)) and pred[u] will contain the parent vertex of u in some spanning tree of the connected component to which u belongs, unless u is the first vertex visited in its component, in which case pred[u] will be u itself.
The spanning trees produced by BFS tend to be broad, with high branching factor, unlike those produced by DFS, which tend to be tall and thin.