Asymptotic analysis
In theoretical computer science, asymptotic analysis is the most frequently used technique to quantify the performance of an algorithm. Its name refers to the fact that this form of analysis neglects the exact amount of time or memory that the algorithm uses on specific cases, but is concerned only with the algorithm's asymptotic behaviour—that is, how the algorithm performs in the limit of infinite problem size.
Contents
Irrelevance of constant factor
It does this by neglecting the so-called invisible constant factor. The reasoning is as follows. Suppose Alice and Bob each write a program to solve the same task. Whenever Alice's program and Bob's program are executed with the same input on a given machine (which we'll call ALOPEX), Alice's program is always about 25% faster than Bob's program. The table below shows the number of lines of input in the first column, the execution time of Alice's program in the second, and the execution time of Bob's program in the third:
| N | Alice | Bob |
|---|---|---|
| 104 | 0.026 | 0.032 |
| 105 | 0.36 | 0.45 |
| 106 | 3.8 | 4.7 |
Practically speaking, Alice's program is faster. In theory, however, the two programs have equally efficient algorithms. This is because an algorithm is an abstraction independent of the machine on which it runs, and we could make Bob's program just as fast as Alice's by running it on a computer that is 25% faster than the original one.
If this argument sounds unconvincing, consider the following argument. Programs, as they run on real machines, are built up from a series of very simple instructions, each of which is executed in a period of time on the order of a nanosecond on a typical microcomputer. However, some instructions happen to be faster than others.
Now, suppose we have the following information:
- On ALOPEX, the
MULTIPLYinstruction takes 1 nanosecond to run whereas theDIVIDEinstruction takes 2 nanoseconds to run. - We have another machine, which we'll call KITSUNE, on which these two instructions both take 1.5 nanoseconds to run.
- When Bob's program is given 150000 lines of input, it uses 1.0×108 multiplications and 3.0×108 divisions, whereas Alice's program uses 4.0×108 multiplications and 0.8×108 divisions on the same input.
Then we see that:
- On ALOPEX, Bob's program will require (1 ns)×(1.0×108) + (2 ns)×(3.0×108) = 0.70 s to complete all these instructions, whereas Alice's program will require (1 ns)×(4.0×108) + (2 ns)×(0.8×108) = 0.56 s; Alice's program is faster by 25%.
- On KITSUNE, Bob's program will require (1.5 ns)×(1.0×108) + (1.5 ns)×(3.0×108) = 0.60 s, whereas Alice's will require (1.5 ns)×(4.0×108) + (1.5 ns)×(0.8×108) = 0.72 s. Now Bob's program is 20% faster than Alice's.
Thus, we see that a program that is faster on one machine is not necessarily faster on another machine, so that comparing exact running times in order to decide which algorithm is faster is not meaningful.
The same can be said about memory usage. On a 32-bit machine, an int (integer data type in the C programming language) and an int* (a pointer to an int) each occupy 4 bytes of memory, whereas on a 64-bit machine, an int uses 4 bytes and an int* uses 8 bytes; so that an algorithm that uses more pointers than integers may use more memory on a 64-bit machine and less on a 32-bit machine when compared to a competing algorithm that uses more integers than pointers.
Why the machine is now irrelevant
The preceding section should convince you that if two programs's running times differ by at most a constant factor, then their algorithms should be considered equally efficient, as we can make one or the other faster in practice just by designing our machine accordingly. Let's now consider a case in which one algorithm can actually be faster than another.
Suppose that Alice and Bob are now given a new problem to solve and their algorithms perform as follows on ALOPEX:
| N | Alice | Bob |
|---|---|---|
| 103 | 0.040 | 0.0013 |
| 104 | 0.38 | 0.13 |
| 105 | 3.7 | 12 |
| 106 | 37 | 1500 |
Observe that when we multiply the problem size by 10, Alice's program takes about 10 times longer, but Bob's program takes about 100 times longer. Thus, even though Bob's program is faster than Alice's program for small inputs (10000 lines or fewer), in the limit of infinite problem size, Alice's program will always be faster. Even if we run Bob's program on a supercomputer and Alice's program on a 386, for sufficiently large input, Alice's program will always finish first, since no matter how much of a disadvantage Alice's program has, it catches up more and more as we increase the problem size; it scales better than Bob's algorithm.
Also observe that Alice's algorithm has running time approximately proportional to the size of its input, whereas Bob's algorithm has running time approximately proportional to the square of the size of its input. We write that Alice's algorithm has running time 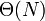 whereas Bob's has running time
whereas Bob's has running time 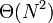 . Notice that we don't bother to write the constant factor, since this varies from machine to machine; we write only the part that tells us how the algorithm scales. Since
. Notice that we don't bother to write the constant factor, since this varies from machine to machine; we write only the part that tells us how the algorithm scales. Since 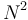 grows much more quickly than
grows much more quickly than 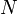 as increases, we see that Bob's algorithm is slower than Alice's.
as increases, we see that Bob's algorithm is slower than Alice's.
Notation
We are now ready to give an explanation of the 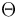 -notation used in the previous section. (See section Big theta notation below.) We suppose that functions
-notation used in the previous section. (See section Big theta notation below.) We suppose that functions 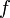 and
and 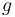 map the positive integers to the positive real numbers. The interpretation is that
map the positive integers to the positive real numbers. The interpretation is that 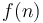 represents the amount of time (in some units) that it takes a certain algorithm to process an input of size
represents the amount of time (in some units) that it takes a certain algorithm to process an input of size 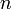 when run on a certain machine.
when run on a certain machine.
Big O notation
We say that 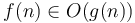 when
when 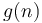 is asymptotically at least as large as . This is read f is big-O of g. Mathematically, this is defined to mean that there are some constants
is asymptotically at least as large as . This is read f is big-O of g. Mathematically, this is defined to mean that there are some constants 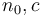 such that
such that 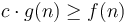 for all
for all 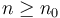 ; to read it idiomatically, for sufficiently large , is bounded by a constant times .
; to read it idiomatically, for sufficiently large , is bounded by a constant times .
This means that if we plotted and on the same set of axes, with along the positive x-axis, then we can scale the curve such that it always lies above the curve .
For example, if we plot 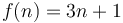 and
and 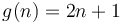 on the same set of axes, then we see that by scaling by a factor of
on the same set of axes, then we see that by scaling by a factor of 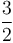 , we can make the curve of lie above the curve of . Therefore,
, we can make the curve of lie above the curve of . Therefore, 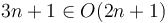 .
.
Similarly, if we plot 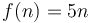 and
and 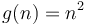 on the same set of axes, and we scale by a factor of 5, we will make the curve of lie above the curve of . So
on the same set of axes, and we scale by a factor of 5, we will make the curve of lie above the curve of . So 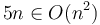 .
.
On the other hand, if 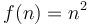 and
and 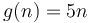 , no matter how much we scale , we cannot make it lie above . We could for example try scaling by a factor of 100. Then, we will have
, no matter how much we scale , we cannot make it lie above . We could for example try scaling by a factor of 100. Then, we will have 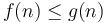 for all up to 500, but for
for all up to 500, but for 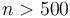 , will be larger. If we try scaling by a factor of 1000, then will still catch up at
, will be larger. If we try scaling by a factor of 1000, then will still catch up at 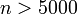 , and so on. So
, and so on. So 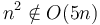 .
.
Big O notation is the most frequently used notation for describing an algorithm's running time, since it provides an upper bound. If, for example, we write that an algorithm's running time is 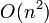 , then this is a guarantee that, as grows larger, the relative increase in the algorithm's running time is at most that of
, then this is a guarantee that, as grows larger, the relative increase in the algorithm's running time is at most that of 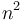 , so that when we double , our algorithm's running time will be at most quadrupled, and so on. This characterization is machine-independent; if an algorithm is on one machine then it will be on any other machine as well. (This holds true under the assumption that they are both classical von Neumann machines, which is the case for all computing machines on Earth right now.)
, so that when we double , our algorithm's running time will be at most quadrupled, and so on. This characterization is machine-independent; if an algorithm is on one machine then it will be on any other machine as well. (This holds true under the assumption that they are both classical von Neumann machines, which is the case for all computing machines on Earth right now.)
An algorithm that is 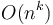 for some constant
for some constant 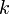 is said to be polynomial-time; its running time is bounded above by a polynomial in its input size. Polynomial-time algorithms are considered "efficient", because they provide the guarantee that as we double the problem size, the running time increases by a factor of at most
is said to be polynomial-time; its running time is bounded above by a polynomial in its input size. Polynomial-time algorithms are considered "efficient", because they provide the guarantee that as we double the problem size, the running time increases by a factor of at most 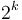 . If an algorithm is not polynomial-time, it could be that doubling the problem size from 1000 to 2000 increases the running time by a factor of 10, but doubling the problem size from 10000 to 20000 increases the running time by a factor of 100, and the factor becomes worse and worse as the problem size increases; these algorithms are considered inefficient. The first polynomial-time algorithm discovered that solves a particular problem is usually considered a breakthrough.
. If an algorithm is not polynomial-time, it could be that doubling the problem size from 1000 to 2000 increases the running time by a factor of 10, but doubling the problem size from 10000 to 20000 increases the running time by a factor of 100, and the factor becomes worse and worse as the problem size increases; these algorithms are considered inefficient. The first polynomial-time algorithm discovered that solves a particular problem is usually considered a breakthrough.
Big omega notation
Big omega notation is the opposite of big O notation. The statement that is equivalent to the statement that 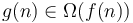 . Conceptually, it means that is asymptotically at least as large as . Therefore, big omega notation provides a lower bound, instead of an upper bound. For example, if an algorithm's running time is
. Conceptually, it means that is asymptotically at least as large as . Therefore, big omega notation provides a lower bound, instead of an upper bound. For example, if an algorithm's running time is 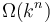 for some
for some 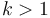 , then when we increase the problem size from to
, then when we increase the problem size from to  , the running time of our algorithm will increase by a factor of at least
, the running time of our algorithm will increase by a factor of at least 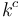 . Approximately doubling the input size will then approximately square the running time. This scaling behaviour, called exponential time, is considered extremely inefficient.
. Approximately doubling the input size will then approximately square the running time. This scaling behaviour, called exponential time, is considered extremely inefficient.
Big theta notation
If and 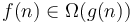 , then and differ by only a constant factor from each other, like the running time of Alice and Bob's algorithms from the first section. In this case, we write
, then and differ by only a constant factor from each other, like the running time of Alice and Bob's algorithms from the first section. In this case, we write 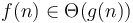 or equivalently
or equivalently 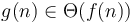 . Whereas big O notation gives us an upper bound on a function, such as an algorithm's running time as a function of its input size, and big omega notation gives us a lower bound, big theta notation gives us both simultaneously—it gives us an expectation of that function. This is often expressed as f is on the order of g.
. Whereas big O notation gives us an upper bound on a function, such as an algorithm's running time as a function of its input size, and big omega notation gives us a lower bound, big theta notation gives us both simultaneously—it gives us an expectation of that function. This is often expressed as f is on the order of g.
Thus, if an algorithm's running time is 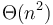 , and we double the input size , then we have an expectation that the running time of the algorithm will be nearly exactly four times what it was before, whereas big O notation would only tell us that it is not more than four times greater, and big omega notation that it is at least four times greater.
, and we double the input size , then we have an expectation that the running time of the algorithm will be nearly exactly four times what it was before, whereas big O notation would only tell us that it is not more than four times greater, and big omega notation that it is at least four times greater.
Little O notation
Whereas the big O notation expresses that grows at least as quickly as in an asymptotic, constant-factor-oblivious sense, little O notation, as in 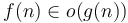 , expresses that grows strictly more quickly than in the limit of infinite . It means that
, expresses that grows strictly more quickly than in the limit of infinite . It means that 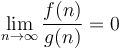 . This notation is not used very often in computer science (simply because it is rarely useful).
. This notation is not used very often in computer science (simply because it is rarely useful).
Little omega notation
Little omega notation is the opposite of little O notation; the statement that is equivalent to the statement that 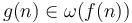 . Little omega notation, like little O notation, is rarely used in computer science.
. Little omega notation, like little O notation, is rarely used in computer science.
Tilde/swung dash
The notation 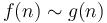 means that
means that 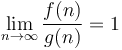 . This is usually not used when discussing running times of algorithms, because it does not ignore the constant factor the way that the other notations do; hence
. This is usually not used when discussing running times of algorithms, because it does not ignore the constant factor the way that the other notations do; hence 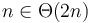 but
but 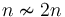 . On the other hand,
. On the other hand, 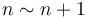 . However, this notation may be useful when we care about the constant factor because we are quantifying something that depends on only the algorithm itself instead of the machine it runs on. For example, the amount of time an algorithm uses to sort its input depends on what machine it runs on, but the number of comparisons that the algorithm uses for a given input does not depend on the machine. In this case we might say that one algorithm requires
. However, this notation may be useful when we care about the constant factor because we are quantifying something that depends on only the algorithm itself instead of the machine it runs on. For example, the amount of time an algorithm uses to sort its input depends on what machine it runs on, but the number of comparisons that the algorithm uses for a given input does not depend on the machine. In this case we might say that one algorithm requires 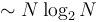 comparisons, whereas another requires
comparisons, whereas another requires 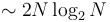 comparisons. Both algorithms are
comparisons. Both algorithms are 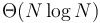 , but the tilde notation distinguishes their performance.
, but the tilde notation distinguishes their performance.