Difference between revisions of "Knuth–Morris–Pratt algorithm"
| Line 14: | Line 14: | ||
==Concept== | ==Concept== | ||
The examples above show that the KMP algorithm relies on noticing that certain substrings of the needle match or do not match other substrings of the needle, but it is probably not clear what the unifying organizational principle for all this match information is. Here it is: | The examples above show that the KMP algorithm relies on noticing that certain substrings of the needle match or do not match other substrings of the needle, but it is probably not clear what the unifying organizational principle for all this match information is. Here it is: | ||
| − | :''At each position <math>i</math> of <math>S</math>, find the longest | + | :''At each position <math>i</math> of <math>S</math>, find the longest proper suffix of the prefix of <math>S</math> of length <math>i</math> that is also a prefix of <math>S</math>.'' |
| − | We shall denote the length of this substring by <math>\pi_i</math>, following <ref name="CLRS">Thomas H. Cormen; Charles E. Leiserson, Ronald L. Rivest, Clifford Stein (2001). "Section 32.4: The Knuth-Morris-Pratt algorithm". ''Introduction to Algorithms'' (Second ed.). MIT Press and McGraw-Hill. pp. 923–931. ISBN 978-0-262-03293-3.</ref>. We can also state the definition of <math>\pi_i</math> equivalently as ''the length of the longest | + | We shall denote the length of this substring by <math>\pi_i</math>, following <ref name="CLRS">Thomas H. Cormen; Charles E. Leiserson, Ronald L. Rivest, Clifford Stein (2001). "Section 32.4: The Knuth-Morris-Pratt algorithm". ''Introduction to Algorithms'' (Second ed.). MIT Press and McGraw-Hill. pp. 923–931. ISBN 978-0-262-03293-3.</ref>. We can also state the definition of <math>\pi_i</math> equivalently as ''the length of the longest substring with length less than <math>i</math> ending at <math>S_i</math> which is also a prefix of <math>S</math>''. |
The table <math>\pi</math>, called the ''prefix function'', occupies linear space, and, as we shall see, can be computed in linear time. It contains ''all'' the information we need in order to execute the "smart" searching techniques described in the examples. In particular, in examples 1 and 2, we used the fact that <math>\pi_3 = 2</math>, that is, the prefix '''aa''' matches the suffix '''aa'''. In example 3, we used the facts that <math>\pi_5 = 2</math>. This tells us that the prefix '''ta''' matches the substring '''ta''' ending at the fifth position. In general, the table <math>\pi</math> tells us, after either a successful match or a mismatch, what the next position is that we should check in the haystack. Comparison proceeds from where it was left off, never revisiting a character of the haystack after we have examined the next one. | The table <math>\pi</math>, called the ''prefix function'', occupies linear space, and, as we shall see, can be computed in linear time. It contains ''all'' the information we need in order to execute the "smart" searching techniques described in the examples. In particular, in examples 1 and 2, we used the fact that <math>\pi_3 = 2</math>, that is, the prefix '''aa''' matches the suffix '''aa'''. In example 3, we used the facts that <math>\pi_5 = 2</math>. This tells us that the prefix '''ta''' matches the substring '''ta''' ending at the fifth position. In general, the table <math>\pi</math> tells us, after either a successful match or a mismatch, what the next position is that we should check in the haystack. Comparison proceeds from where it was left off, never revisiting a character of the haystack after we have examined the next one. | ||
| Line 24: | Line 24: | ||
That is, we can enumerate all substrings ending at <math>S_i</math> that are prefixes of <math>S</math> by starting with <math>i</math>, looking it up in the table <math>\pi</math>, looking up the result, looking up the result, and so on, giving a strictly decreasing sequence, terminating with zero. | That is, we can enumerate all substrings ending at <math>S_i</math> that are prefixes of <math>S</math> by starting with <math>i</math>, looking it up in the table <math>\pi</math>, looking up the result, looking up the result, and so on, giving a strictly decreasing sequence, terminating with zero. | ||
:''Proof'': We first show by induction that if <math>j</math> appears in the sequence <math>\pi^*_i</math> then the prefix <math>S_1, S_2, \ldots, S_j</math> matches the substring <math>S_{i-j+1}, S_{i-j+2}, \ldots, S_i</math>, ''i.e'', <math>j</math> indeed belongs in the sequence <math>\pi^*_i</math>. Suppose <math>j</math> is the first entry in <math>\pi^*_i</math>. Then <math>j = i</math> and it trivially belongs (''i.e'', the prefix of length <math>i</math> matches itself). Now suppose <math>j</math> is not the first entry, but is preceded by the entry <math>k</math> which is valid. This means that the prefix of length <math>j</math> is a suffix of the prefix of length <math>k</math>. But the prefix of length <math>k</math> matches the substring of length <math>k</math> ending at <math>S_i</math> by assumption. So the prefix of length <math>j</math> is a suffix of the substring of length <math>k</math> ending at <math>S_i</math>. Therefore the prefix of length <math>j</math> matches the substring of length <math>j</math> ending at <math>S_i</math> (since <math>j < k</math>). | :''Proof'': We first show by induction that if <math>j</math> appears in the sequence <math>\pi^*_i</math> then the prefix <math>S_1, S_2, \ldots, S_j</math> matches the substring <math>S_{i-j+1}, S_{i-j+2}, \ldots, S_i</math>, ''i.e'', <math>j</math> indeed belongs in the sequence <math>\pi^*_i</math>. Suppose <math>j</math> is the first entry in <math>\pi^*_i</math>. Then <math>j = i</math> and it trivially belongs (''i.e'', the prefix of length <math>i</math> matches itself). Now suppose <math>j</math> is not the first entry, but is preceded by the entry <math>k</math> which is valid. This means that the prefix of length <math>j</math> is a suffix of the prefix of length <math>k</math>. But the prefix of length <math>k</math> matches the substring of length <math>k</math> ending at <math>S_i</math> by assumption. So the prefix of length <math>j</math> is a suffix of the substring of length <math>k</math> ending at <math>S_i</math>. Therefore the prefix of length <math>j</math> matches the substring of length <math>j</math> ending at <math>S_i</math> (since <math>j < k</math>). | ||
| − | :We now show by contradiction that if the prefix of length <math>j</math> matches the suffix of length <math>j</math> of the prefix of length <math>i</math>, ''i.e.'', if <math>j</math> "belongs" in the sequence <math>\pi^*_i</math>, then it appears in this sequence. Assume <math>j</math> does not appear in the sequence. Clearly <math>0 < j < i</math> since 0 and <math>i</math> both appear. Since <math>\pi^*_i</math> is strictly decreasing, we can find exactly one <math>k \in \pi^*_i</math> such that <math>k > j</math> and <math>\pi_k < j</math>; that is, we can find exactly one <math>k</math> after which <math>j</math> "should" appear (to keep the sequence decreasing). | + | :We now show by contradiction that if the prefix of length <math>j</math> matches the suffix of length <math>j</math> of the prefix of length <math>i</math>, ''i.e.'', if <math>j</math> "belongs" in the sequence <math>\pi^*_i</math>, then it appears in this sequence. Assume <math>j</math> does not appear in the sequence. Clearly <math>0 < j < i</math> since 0 and <math>i</math> both appear. Since <math>\pi^*_i</math> is strictly decreasing, we can find exactly one <math>k \in \pi^*_i</math> such that <math>k > j</math> and <math>\pi_k < j</math>; that is, we can find exactly one <math>k</math> after which <math>j</math> "should" appear (to keep the sequence decreasing). We know from the first part of the proof that the substring ending at <math>S_i</math> with length <math>k</math> is also a prefix of <math>S</math>. Since the substring of length <math>j</math> ending at <math>S_i</math> is a suffix of the substring of length <math>k</math> ending at <math>S_i</math>, it follows that the substring of length <math>j</math> ending at <math>S_i</math> matches the suffix of length <math>j</math> of the prefix of length <math>k</math>. But the substring of length <math>j</math> ending at <math>S_i</math> also matches the prefix of length <math>j</math>, so the prefix of length <math>j</math> matches the suffix of length <math>j</math> of the prefix of length <math>k</math>. We therefore conclude that <math>\pi_k \geq j</math>. But <math>j > \pi_k</math>, a contradiction. <math>_\blacksquare</math> |
| + | With this in mind, we can design an algorithm to compute the table <math>\pi</math>. For each <math>i</math>, we will first try to find a nonempty proper suffix of the prefix of length <math>i</math> that is also a prefix of <math>S</math>. If we fail to do so, we will conclude that <math>\pi_i = 0</math> (clearly this is the case when <math>i = 1</math>.) Observe that if we do find a nonempty proper suffix of <math>S_i</math> that is also a prefix of <math>S</math>, and that this suffix has length <math>k</math>, then, by removing the last character from this suffix, we obtain a nonempty proper suffix of the prefix of length <math>i-1</math> that is also a prefix of <math>S</math>. Therefore, if we enumerate ''all'' nonempty proper suffixes of the prefix of length <math>i-1</math> that are also prefixes of <math>S</math>, the ''longest'' of these ''that can be extended'' (because the character after this prefix equals the character <math>S_i</math>, so that it can be added to the end of both the prefix and the suffix to give a suffix of the prefix of length <math>i</math> that is also a prefix of <math>S</math>) gives the value of <math>\pi_i</math>. So we will let <math>k = \pi_{i-1}</math> and keep iterating through the sequence <math>\pi_k, \pi_{\pi_k}, \ldots</math>. We stop if we reach element <math>j</math> in this sequence such that <math>S_{j+1} = S_i</math>, and declare <math>\pi_i = j+1</math>; this always gives an optimal solution since the sequence <math>\pi^*_i</math> is decreasing. If we exhaust the sequence, then <math>\pi_i = 0</math>. | ||
| + | |||
| + | Here is the pseudocode: | ||
| + | <pre> | ||
| + | π[1] ← 0 | ||
| + | k ← 0 | ||
| + | for i ∈ [2..m] | ||
| + | while k > 0 and S[k+1] ≠ S[i] | ||
| + | k ← π[k] | ||
| + | if k ≠ 0 | ||
| + | k ← k+1 | ||
| + | π[i] ← k | ||
| + | </pre> | ||
| + | This algorithm takes <math>O(m)</math> time to execute. To see this, notice that the value of <code>k</code> is never negative; therefore it cannot decrease more than it increases. It only increases in the line <code>k ← k+1</code>, which can only be executed up to <math>m-1</math> times. Therefore <code>k</code> can be decreased at most <code>k</code> times. But <code>k</code> is decreased in each iteration of the while loop, so the while loop can only run a linear number of times overall. All the other instructions in the for loop take constant time per iteration, so linear time overall. | ||
==References== | ==References== | ||
<references/> | <references/> | ||
Revision as of 01:33, 4 April 2011
The Knuth–Morris–Pratt (KMP) algorithm is a linear time solution to the single-pattern string search problem. It is based on the observation that a partial match gives useful information about whether or not the needle may partially match subsequent positions in the haystack. This is because a partial match indicates that some part of the haystack is the same as some part of the needle, so that if we have preprocessed the needle in the right way, we will be able to draw some conclusions about the contents of the haystack (because of the partial match) without having to go back and re-examine characters already matched. In particular, this means that, in a certain sense, we will want to precompute how the needle matches itself. The algorithm thus "never looks back" and makes a single pass over the haystack. Together with linear time preprocessing of the needle, this gives a linear time algorithm overall.
Contents
Motivation
The motivation behind KMP is best illustrated using a few simple examples.
Example 1
In this example, we are searching for the string 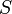 = aaa in the string
= aaa in the string 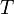 = aaaaaaaaa (in which it occurs seven times). The naive algorithm would begin by comparing
= aaaaaaaaa (in which it occurs seven times). The naive algorithm would begin by comparing 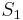 with
with 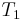 ,
, 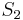 with
with 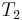 , and
, and 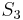 with
with 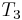 , and thus find a match for at position 1 of . Then it would proceed to compare with , with , and with
, and thus find a match for at position 1 of . Then it would proceed to compare with , with , and with 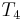 , and thus find a match at position 2 of , and so on, until it finds all the matches. But we can do better than this, if we preprocess and note that and are the same, and and are the same. That is, the prefix of length 2 in matches the substring of length 2 starting at position 2 in ; partially matches itself. Now, after finding that
, and thus find a match at position 2 of , and so on, until it finds all the matches. But we can do better than this, if we preprocess and note that and are the same, and and are the same. That is, the prefix of length 2 in matches the substring of length 2 starting at position 2 in ; partially matches itself. Now, after finding that 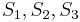 match
match 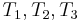 , respectively, we no longer care about , since we are trying to find a match at position 2 now, but we still know that
, respectively, we no longer care about , since we are trying to find a match at position 2 now, but we still know that 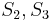 match
match 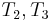 respectively. Since we already know
respectively. Since we already know 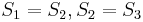 , we now know that
, we now know that 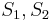 match respectively; there is no need to examine and again, as the naive algorithm would do. If we now check that matches , then, after finding at position 1 in , we only need to do one more comparison (not three) to conclude that also occurs at position 2 in . So now we know that match
match respectively; there is no need to examine and again, as the naive algorithm would do. If we now check that matches , then, after finding at position 1 in , we only need to do one more comparison (not three) to conclude that also occurs at position 2 in . So now we know that match 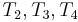 , respectively, which allows us to conclude that match
, respectively, which allows us to conclude that match 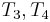 . Then we compare with
. Then we compare with 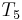 , and find another match, and so on. Whereas the naive algorithm needs three comparisons to find each occurrence of in , our technique only needs three comparisons to find the first occurrence, and only one for each after that, and doesn't go back to examine previous characters of again. (This is how a human would probably do this search, too.
, and find another match, and so on. Whereas the naive algorithm needs three comparisons to find each occurrence of in , our technique only needs three comparisons to find the first occurrence, and only one for each after that, and doesn't go back to examine previous characters of again. (This is how a human would probably do this search, too.
Example 2
Now let's search for the string = aaa in the string = aabaabaaa. Again, we start out the same way as in the naive algorithm, hence, we compare with , with , and with . Here we find a mismatch between and , so does not occur at position 1 in . Now, the naive algorithm would continue by comparing with and with , and would find a mismatch; then it would compare with , and find a mismatch, and so on. But a human would notice that after the first mismatch, the possibilities of finding at positions 2 and 3 in are extinguished. This is because, as noted in Example 1, is the same as , and since 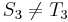 ,
, 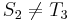 also (so we will not find at position 2 of ). And, likewise, since
also (so we will not find at position 2 of ). And, likewise, since 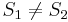 , and , it is also true that
, and , it is also true that 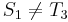 , so it is pointless looking for a match at the third position of . Thus, it would make sense to start comparing again at the fourth position of (i.e., with
, so it is pointless looking for a match at the third position of . Thus, it would make sense to start comparing again at the fourth position of (i.e., with 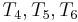 , respectively). Again finding a mismatch, we use similar reasoning to rule out the fifth and sixth positions in , and begin matching again at
, respectively). Again finding a mismatch, we use similar reasoning to rule out the fifth and sixth positions in , and begin matching again at 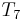 (where we finally find a match.) Again, notice that the characters of were examined strictly in order.
(where we finally find a match.) Again, notice that the characters of were examined strictly in order.
Example 3
As a more complex example, imagine searching for the string = tartan in the string = tartaric_acid. We make the observation that the prefix of length 2 in matches the substring of length 2 in starting from position 4. Now, we start by comparing 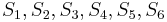 with
with 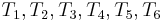 , respectively. We find that
, respectively. We find that 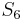 does not match
does not match 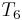 , so there is no match at position 1. At this point, we note that since and
, so there is no match at position 1. At this point, we note that since and 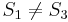 , and
, and 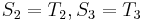 , obviously,
, obviously, 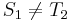 and , so there cannot be a match at position 2 or position 3. Now, recall that
and , so there cannot be a match at position 2 or position 3. Now, recall that 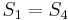 and
and 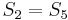 , and that
, and that 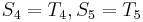 . We can translate this to
. We can translate this to 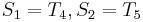 . So we proceed to compare with . In this way, we have ruled out two possible positions, and we have restarted comparing not at the beginning of but in the middle, avoiding re-examining and .
. So we proceed to compare with . In this way, we have ruled out two possible positions, and we have restarted comparing not at the beginning of but in the middle, avoiding re-examining and .
Concept
The examples above show that the KMP algorithm relies on noticing that certain substrings of the needle match or do not match other substrings of the needle, but it is probably not clear what the unifying organizational principle for all this match information is. Here it is:
- At each position
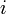 of , find the longest proper suffix of the prefix of of length that is also a prefix of .
of , find the longest proper suffix of the prefix of of length that is also a prefix of .
We shall denote the length of this substring by 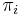 , following [1]. We can also state the definition of equivalently as the length of the longest substring with length less than ending at
, following [1]. We can also state the definition of equivalently as the length of the longest substring with length less than ending at 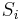 which is also a prefix of .
which is also a prefix of .
The table 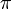 , called the prefix function, occupies linear space, and, as we shall see, can be computed in linear time. It contains all the information we need in order to execute the "smart" searching techniques described in the examples. In particular, in examples 1 and 2, we used the fact that
, called the prefix function, occupies linear space, and, as we shall see, can be computed in linear time. It contains all the information we need in order to execute the "smart" searching techniques described in the examples. In particular, in examples 1 and 2, we used the fact that 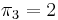 , that is, the prefix aa matches the suffix aa. In example 3, we used the facts that
, that is, the prefix aa matches the suffix aa. In example 3, we used the facts that 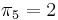 . This tells us that the prefix ta matches the substring ta ending at the fifth position. In general, the table tells us, after either a successful match or a mismatch, what the next position is that we should check in the haystack. Comparison proceeds from where it was left off, never revisiting a character of the haystack after we have examined the next one.
. This tells us that the prefix ta matches the substring ta ending at the fifth position. In general, the table tells us, after either a successful match or a mismatch, what the next position is that we should check in the haystack. Comparison proceeds from where it was left off, never revisiting a character of the haystack after we have examined the next one.
Computation of the prefix function
To compute the prefix function, we shall first make the following observation:
- Prefix function iteration lemma[1]: The sequence
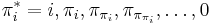 contains exactly those values
contains exactly those values 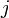 such that the prefix of of length matches the substring of length ending at .
such that the prefix of of length matches the substring of length ending at .
That is, we can enumerate all substrings ending at that are prefixes of by starting with , looking it up in the table , looking up the result, looking up the result, and so on, giving a strictly decreasing sequence, terminating with zero.
- Proof: We first show by induction that if appears in the sequence
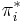 then the prefix
then the prefix 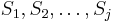 matches the substring
matches the substring 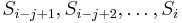 , i.e, indeed belongs in the sequence . Suppose is the first entry in . Then
, i.e, indeed belongs in the sequence . Suppose is the first entry in . Then 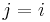 and it trivially belongs (i.e, the prefix of length matches itself). Now suppose is not the first entry, but is preceded by the entry
and it trivially belongs (i.e, the prefix of length matches itself). Now suppose is not the first entry, but is preceded by the entry 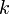 which is valid. This means that the prefix of length is a suffix of the prefix of length . But the prefix of length matches the substring of length ending at by assumption. So the prefix of length is a suffix of the substring of length ending at . Therefore the prefix of length matches the substring of length ending at (since
which is valid. This means that the prefix of length is a suffix of the prefix of length . But the prefix of length matches the substring of length ending at by assumption. So the prefix of length is a suffix of the substring of length ending at . Therefore the prefix of length matches the substring of length ending at (since 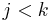 ).
). - We now show by contradiction that if the prefix of length matches the suffix of length of the prefix of length , i.e., if "belongs" in the sequence , then it appears in this sequence. Assume does not appear in the sequence. Clearly
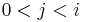 since 0 and both appear. Since is strictly decreasing, we can find exactly one
since 0 and both appear. Since is strictly decreasing, we can find exactly one 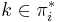 such that
such that 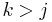 and
and 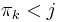 ; that is, we can find exactly one after which "should" appear (to keep the sequence decreasing). We know from the first part of the proof that the substring ending at with length is also a prefix of . Since the substring of length ending at is a suffix of the substring of length ending at , it follows that the substring of length ending at matches the suffix of length of the prefix of length . But the substring of length ending at also matches the prefix of length , so the prefix of length matches the suffix of length of the prefix of length . We therefore conclude that
; that is, we can find exactly one after which "should" appear (to keep the sequence decreasing). We know from the first part of the proof that the substring ending at with length is also a prefix of . Since the substring of length ending at is a suffix of the substring of length ending at , it follows that the substring of length ending at matches the suffix of length of the prefix of length . But the substring of length ending at also matches the prefix of length , so the prefix of length matches the suffix of length of the prefix of length . We therefore conclude that 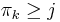 . But
. But 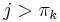 , a contradiction.
, a contradiction. 
With this in mind, we can design an algorithm to compute the table . For each , we will first try to find a nonempty proper suffix of the prefix of length that is also a prefix of . If we fail to do so, we will conclude that 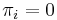 (clearly this is the case when
(clearly this is the case when 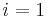 .) Observe that if we do find a nonempty proper suffix of that is also a prefix of , and that this suffix has length , then, by removing the last character from this suffix, we obtain a nonempty proper suffix of the prefix of length
.) Observe that if we do find a nonempty proper suffix of that is also a prefix of , and that this suffix has length , then, by removing the last character from this suffix, we obtain a nonempty proper suffix of the prefix of length 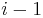 that is also a prefix of . Therefore, if we enumerate all nonempty proper suffixes of the prefix of length that are also prefixes of , the longest of these that can be extended (because the character after this prefix equals the character , so that it can be added to the end of both the prefix and the suffix to give a suffix of the prefix of length that is also a prefix of ) gives the value of . So we will let
that is also a prefix of . Therefore, if we enumerate all nonempty proper suffixes of the prefix of length that are also prefixes of , the longest of these that can be extended (because the character after this prefix equals the character , so that it can be added to the end of both the prefix and the suffix to give a suffix of the prefix of length that is also a prefix of ) gives the value of . So we will let 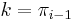 and keep iterating through the sequence
and keep iterating through the sequence 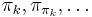 . We stop if we reach element in this sequence such that
. We stop if we reach element in this sequence such that 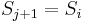 , and declare
, and declare 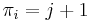 ; this always gives an optimal solution since the sequence is decreasing. If we exhaust the sequence, then .
; this always gives an optimal solution since the sequence is decreasing. If we exhaust the sequence, then .
Here is the pseudocode:
π[1] ← 0
k ← 0
for i ∈ [2..m]
while k > 0 and S[k+1] ≠ S[i]
k ← π[k]
if k ≠ 0
k ← k+1
π[i] ← k
This algorithm takes 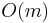 time to execute. To see this, notice that the value of
time to execute. To see this, notice that the value of k is never negative; therefore it cannot decrease more than it increases. It only increases in the line k ← k+1, which can only be executed up to 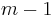 times. Therefore
times. Therefore k can be decreased at most k times. But k is decreased in each iteration of the while loop, so the while loop can only run a linear number of times overall. All the other instructions in the for loop take constant time per iteration, so linear time overall.
References
- ↑ 1.0 1.1 Thomas H. Cormen; Charles E. Leiserson, Ronald L. Rivest, Clifford Stein (2001). "Section 32.4: The Knuth-Morris-Pratt algorithm". Introduction to Algorithms (Second ed.). MIT Press and McGraw-Hill. pp. 923–931. ISBN 978-0-262-03293-3.