Maximum subvector sum
The maximum subvector sum problem is that of finding a segment of a vector (array of numbers)[1], possibly empty, with maximum sum. If all elements of the array are nonnegative, then the problem may be trivially solved by taking the entire vector; if all elements are negative, then the problem is again trivially solved by taking the empty segment (whose sum is conventionally defined to be zero). The problem requires more thought, however, when the vector contains a mixture of positive and negative numbers.
This problem originated in the domain of image processing;[2] applications have also been found in data mining.[3] In algorithmic programming competitions, Kadane's linear time algorithm for this problem is often useful as a building block within a more complex algorithm for processing a multidimensional array.
Contents
One-dimensional problem
Bentley[2] describes four algorithms for this problem, of running time 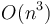 ,
, 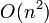 ,
, 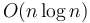 , and
, and 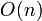 . We discuss only the latter in this article, which is known as Kadane's algorithm after its discoverer.
. We discuss only the latter in this article, which is known as Kadane's algorithm after its discoverer.
Kadane's algorithm is a classic example of dynamic programming. It works by scanning the vector from left to right and computing the maximum-sum subvector ending at each of the vector's entries; denote the best sum ending at entry 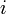 by
by 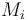 . Also, for convenience, set
. Also, for convenience, set 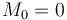 for the empty subvector. The maximum subvector sum for the entire array
for the empty subvector. The maximum subvector sum for the entire array 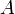 is then, of course,
is then, of course, 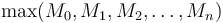 . for
. for 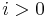 may then be computed as follows:
may then be computed as follows:
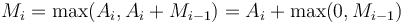
This formula is based on the following optimal substructure: The maximum-sum subvector ending at position consists of either only the element 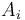 itself, or that element plus one or more elements
itself, or that element plus one or more elements 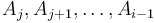 (that is, ending at the previous position
(that is, ending at the previous position 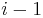 ). But the sum obtained in the latter case is simply plus the sum of the subvector ending at
). But the sum obtained in the latter case is simply plus the sum of the subvector ending at 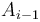 , so we want to make the latter as great as possible, requiring us to choose the maximum-sum subvector ending at . This accounts for the
, so we want to make the latter as great as possible, requiring us to choose the maximum-sum subvector ending at . This accounts for the 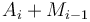 term. Of course, if
term. Of course, if 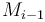 turned out to be negative, then there is no point in including any terms before at all. This is why we must take the greater of and .
turned out to be negative, then there is no point in including any terms before at all. This is why we must take the greater of and .
Example
In the vector [5, -3, -3, 3, 0, -1, 4, -5, 5], the maximal subvector is [3, 0, -1, 4]; this subvector has a sum of 6, which is greater than that of any other subvector. Notice that in order to construct this subvector, we had to take a negative entry because it lay between two large positive entries; if we refused to include any negative entries, the maximum sum obtainable would be only 5 (by taking one of the elements at the ends).
Implementation (C++)
This snippet is a direct translation of the algorithm given in the text:
template<class Vector> int max_subvector_sum(Vector V) { int* M = new int[V.size() + 1]; // dynamically allocate array M M[0] = 0; for (int i = 0; i < V.size(); i++) M[i+1] = V[i] + max(0, M[i]); // apply the formula, but with zero-indexed arrays int res = max_element(M, M+V.size()+1); delete[] M; return res; }
With a bit of thought, this can be simplified. In particular, we don't need to keep the entire array 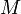 ; we only need to remember the last element computed.
; we only need to remember the last element computed.
template<class Vector> int max_subvector_sum(Vector V) { int res = 0, cur = 0; for (int i = 0; i < V.size(); i++) res = max(res, cur = V[i] + max(0, cur)); return res; }
Higher dimensions
The obvious generalization of the problem is as follows: given a 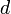 -dimensional array (or tensor) of dimensions
-dimensional array (or tensor) of dimensions 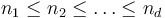 , find indices
, find indices 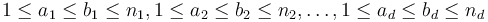 such that the sum
such that the sum 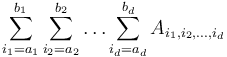 is maximized (or return 0 if all entries are negative).
is maximized (or return 0 if all entries are negative).
We describe a simple algorithm for this problem. It works by recursively reducing a -dimensional problem to 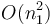 simpler,
simpler,  -dimensional problems, terminating at
-dimensional problems, terminating at 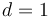 which can be solved in
which can be solved in 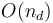 time using the one-dimensional algorithm. Evidently, this algorithm takes time
time using the one-dimensional algorithm. Evidently, this algorithm takes time  . In the case with all dimensions equal, this reduces to
. In the case with all dimensions equal, this reduces to 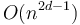 .
.
The details are as follows. We try all possible sets of bounds ![[a_1, b_1] \subseteq [1, n_1]](/wiki/images/math/4/b/a/4ba982291425e57eff77380445ed8ee1.png) for the first index. For each such interval, we create a -dimensional tensor
for the first index. For each such interval, we create a -dimensional tensor 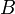 where
where 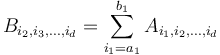 and compute the maximum subtensor sum in . The range of indices that this represents in the original array will be the Cartesian product of the indices in the maximum-sum subtensor of and the original range
and compute the maximum subtensor sum in . The range of indices that this represents in the original array will be the Cartesian product of the indices in the maximum-sum subtensor of and the original range ![[a_1, b_1]](/wiki/images/math/1/f/2/1f2bdcb8e76f233ce0b0677c8a8fc80e.png) , so that by trying all possibilities for the latter, we will account for all possible subtensors of the original array .
, so that by trying all possibilities for the latter, we will account for all possible subtensors of the original array .
Two-dimensional implementation
In two dimensions, the time required is 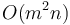 , where
, where 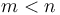 , or if
, or if  . If we imagine a two-dimensional array as a matrix, then the problem is to pick some axis-aligned rectangle within the matrix with maximum sum. The algorithm described above can be written as follows:
. If we imagine a two-dimensional array as a matrix, then the problem is to pick some axis-aligned rectangle within the matrix with maximum sum. The algorithm described above can be written as follows:
template<class Matrix> int max_submatrix_sum(Matrix M) { int m = M.size(); int n = M[0].size(); vector<int> B(n); int res = 0; for (int a = 0; a < m; a++) { fill(B.begin(), B.end(), 0); for (int b = a; b < m; b++) { for (int i = 0; i < n; i++) B[i] += M[b][i]; res = max(res, max_subvector_sum(B)); } } return res; }
Observe that, in the above code, the outer loop fixes 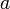 , the starting row, and the middle loop fixes
, the starting row, and the middle loop fixes 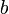 , the ending row. For every combination of starting and ending row, we compute the sum of the elements in those rows for each column; these sums are stored in the vector , which is then passed to the one-dimensional subroutine given earlier in the article. That is,
, the ending row. For every combination of starting and ending row, we compute the sum of the elements in those rows for each column; these sums are stored in the vector , which is then passed to the one-dimensional subroutine given earlier in the article. That is, 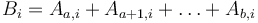 . However, we cannot afford to actually compute each entry of in this way; that would give
. However, we cannot afford to actually compute each entry of in this way; that would give 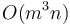 time. Instead, we compute dynamically, by re-using the values from the previous , since
time. Instead, we compute dynamically, by re-using the values from the previous , since 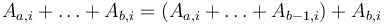 . This accounts for the line
. This accounts for the line B[i] += M[b][i] in the code above.
Faster algorithms
This algorithm is not asymptotically optimal; for example, the 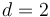 case can be solved in
case can be solved in 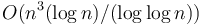 time by a result due to Takaoka.[3] This implies that for
time by a result due to Takaoka.[3] This implies that for 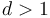 , we can always achieve
, we can always achieve 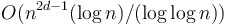 , which is slightly better than the algorithm given above. In practice, however, the gains are not large.
, which is slightly better than the algorithm given above. In practice, however, the gains are not large.
Problems
Notes and references
- ↑ In computer science, vector is often used to mean array of real numbers; sometimes it is simply synonymous with array. Here, array is used in contradistinction with linked list, which does not support efficient random access. This meaning is related to but different from the meaning of the word in mathematics and physics.
- ↑ 2.0 2.1 Bentley, Jon (1984), "Programming pearls: algorithm design techniques", Communications of the ACM 27 (9): 865–873, doi:10.1145/358234.381162.
- ↑ 3.0 3.1 Takaoka, T. (2002), "Efficient algorithms for the maximum subarray problem by distance matrix multiplication", Electronic Notes in Theoretical Computer Science 61.