String
The string is one of the most fundamental objects in computer science. Strings are intimately familiar to us in the form of text and therefore it is no wonder that the theory of strings (which is to be distinguished from the field of theoretical physics known as "string theory") is one of the most extensively studied subdisciplines of computer science.
Definitions[edit]
An alphabet, usually denoted 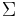 is a finite nonempty set (whose size is denoted
is a finite nonempty set (whose size is denoted 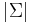 ). It is often assumed that the alphabet is totally ordered, but this is not always necessary. (Since the alphabet is finite, we can always impose a total order when it would be useful to do so, such as when constructing a dictionary.) An element of this the alphabet is known as a character. Unless otherwise specified, we will always assume that two characters from the same alphabet can be compared for equality in constant time.
). It is often assumed that the alphabet is totally ordered, but this is not always necessary. (Since the alphabet is finite, we can always impose a total order when it would be useful to do so, such as when constructing a dictionary.) An element of this the alphabet is known as a character. Unless otherwise specified, we will always assume that two characters from the same alphabet can be compared for equality in constant time.
The set of 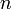 -tuples of is denoted
-tuples of is denoted 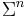 . A string of length is an element of . The set
. A string of length is an element of . The set 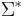 is defined
is defined 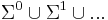 ; an element of is known simply as a string over . The empty string, denoted
; an element of is known simply as a string over . The empty string, denoted 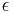 or
or 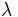 , is the unique element of
, is the unique element of 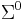 . The length of a string
. The length of a string 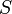 is denoted
is denoted 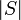 . (Note that the usual definition of "string" requires strings to have finite length, although arbitrarily long strings exist.)
. (Note that the usual definition of "string" requires strings to have finite length, although arbitrarily long strings exist.)
It follows from the definition that all strings are sequences, but not all sequences are strings.
For ease of conceptualization, we shall usually assign a symbol, a graphical representation, to each character of the alphabet and, considering a string as a sequence of characters, render it as a sequence of symbols. We shall usually do so in boldface, but in this section we shall use italics to avoid confusion with terms being defined, hence, PEG. On other occasions we may choose to represent them with the ordered list notation, hence, [P,E,G]. (This form is useful when the symbols consist of more than one glyph, as can be the case when they are integers; see below.) We will often number the characters of strings, sometimes starting from zero, sometimes starting from one.
Examples of alphabets include:
- The binary alphabet, with exactly two characters (
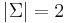 ), usually denoted 0 and 1. In virtually all computers ever built, data are strings over the binary alphabet, and are known as bit strings.
), usually denoted 0 and 1. In virtually all computers ever built, data are strings over the binary alphabet, and are known as bit strings. - The Latin alphabet, with the characters a, A, b, B, ..., z, Z (
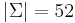 ). English words may be considered strings over the Latin alphabet.
). English words may be considered strings over the Latin alphabet. - The Unicode character set (the size of this alphabet depends somewhat on what we consider to be a valid Unicode character). Text files may be considered strings over this alphabet.
- The set of integers
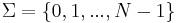 for some
for some 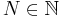 , for which
, for which  . Here the characters are also integers, and their corresponding symbols might have more than one glyph when
. Here the characters are also integers, and their corresponding symbols might have more than one glyph when 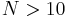 . (Recall that the definition of character is broader than the common concept of the character as the smallest, indivisible element of writing.)
. (Recall that the definition of character is broader than the common concept of the character as the smallest, indivisible element of writing.) - The set of nitrogenous bases in DNA, {A, C, G, T}, with
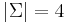 . Codons are considered members of
. Codons are considered members of 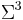 , and DNA sequences members of .
, and DNA sequences members of . - The set of universal proteinogenic amino acids, {A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y} (
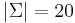 ). The primary structure of a protein is represented as a string over this alphabet. This and the preceding example are important alphabets in bioinformatics.
). The primary structure of a protein is represented as a string over this alphabet. This and the preceding example are important alphabets in bioinformatics.
A substring of a string 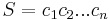 is a string with the same alphabet as given by
is a string with the same alphabet as given by  for some
for some  with
with  . Note that the empty string is considered a substring of all other strings. In other words, it is a series of (possibly zero) characters occurring consecutively in a string, taken in order. For example, the, in, here, and therein are all substrings of therein, as is ; however, tin is not (the characters are not consecutive in the original string), nor is rine (the characters do not occur in order in the original string). A prefix is a substring with
. Note that the empty string is considered a substring of all other strings. In other words, it is a series of (possibly zero) characters occurring consecutively in a string, taken in order. For example, the, in, here, and therein are all substrings of therein, as is ; however, tin is not (the characters are not consecutive in the original string), nor is rine (the characters do not occur in order in the original string). A prefix is a substring with  , so that , the, there, and therein are prefixes of therein. A suffix is a substring with
, so that , the, there, and therein are prefixes of therein. A suffix is a substring with 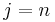 , so that , in, rein, herein, and therein are suffixes of therein. We write
, so that , in, rein, herein, and therein are suffixes of therein. We write 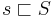 to indicate that
to indicate that  is a prefix of . Likewise the notation
is a prefix of . Likewise the notation  denotes that is a suffix of . We say that is a proper prefix of when and
denotes that is a suffix of . We say that is a proper prefix of when and 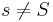 , with proper suffix defined analogously.
, with proper suffix defined analogously.
These examples may have given the misleading impression that strings which do not represent "valid" words, such as ther, are not valid strings. This is entirely untrue; ther is also a valid prefix of therein. The definition of a string says nothing about the validity or meaning of a string. A language is a (possibly empty, often infinite) subset of ; an element of a language is often called a word (although this term should be used with caution). Thus, while every element of is a valid string, not all are necessarily valid words in a language over . For example, let be defined as the Latin alphabet and 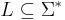 be the language consisting of the representations of all valid English words. (Note that we have been careful to distinguish the words themselves from their representations as strings.) Then ther is certainly a valid string, being an element of , but is not a valid word in
be the language consisting of the representations of all valid English words. (Note that we have been careful to distinguish the words themselves from their representations as strings.) Then ther is certainly a valid string, being an element of , but is not a valid word in 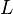 , since it does not represent an English word.
, since it does not represent an English word.
Thus, a string of length 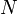 has
has 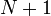 prefixes, suffixes, proper prefixes, proper suffixes, and
prefixes, suffixes, proper prefixes, proper suffixes, and 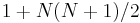 substrings. (Here we consider two substrings to be distinct if they start or end at different indices, except that the empty string is counted only once; see also counting distinct substrings.)
substrings. (Here we consider two substrings to be distinct if they start or end at different indices, except that the empty string is counted only once; see also counting distinct substrings.)
Two strings with the same alphabet can be concatenated. To concatenate two strings is to link them together to give a new string which begins with the first and ends with the second with no overlap. Formally, the concatenation of strings and 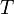 is denoted
is denoted 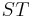 and has the following three properties:
and has the following three properties:
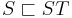

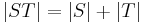
For example, concatenating there and in gives therein. So do concatenating the and rein, or and therein, or therein and . Note that in general, concatenation is not commutative.
Alphabet size[edit]
The size of the alphabet can affect the asymptotic complexity of string algorithms. In particular, if is the size of the input, then we can classify alphabets as follows[1]:
- If
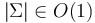 , that is, it is bounded above by a constant independent of , then the alphabet is said to be constant.
, that is, it is bounded above by a constant independent of , then the alphabet is said to be constant. - If the characters are integers bounded by
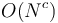 for some
for some 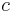 , then the alphabet is said to be integer. (This is equivalent to saying that the characters are integers with at most
, then the alphabet is said to be integer. (This is equivalent to saying that the characters are integers with at most 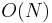 digits.) Note that this implies
digits.) Note that this implies 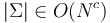 and equivalently
and equivalently 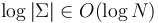 .
. - All alphabets are general, even when they are neither constant nor integer.
The dividing lines may seem arbitrary, but they are placed where they are because for many algorithms a better asymptotic complexity guarantee (in terms of ) may be achieved when the alphabet is constant rather than when it is integer, or when it is integer rather than when it is general. For example, assume that we want to construct a trie of a set of strings of total size using constant space. We need to store the links from each node (of which there may be up to ) to its children. These links should be indexed by character, so that we can trace down a path of characters from root to leaf when looking for a word.
- When the alphabet is constant, we can simply store the child links of each node in an array and walk each link in constant time, and a search will take time (because the trie's height cannot possibly be more than ), and furthermore the space complexity is
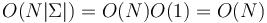 .
. - When the alphabet is integer, this approach will not meet the linear space restriction. Instead, we can store the links at each node in a map (from character to pointer), which will allow us to perform the walk in
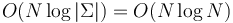 time. The total extra space usage (that is, the total size of all the maps) is proportional to the total size of the maps, which, being equal to the total number of links, is .
time. The total extra space usage (that is, the total size of all the maps) is proportional to the total size of the maps, which, being equal to the total number of links, is . - If the alphabet is general, and we do the same, then the time taken to walk down the tree will be
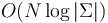 again; but this is no longer bounded by
again; but this is no longer bounded by 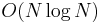 .
.
Treatment in programming languages[edit]
In many programming languages, strings are superficially similar to arrays of characters, in that the syntax for accessing a string's characters usually match the syntax for accessing array elements. Some programming languages, such as C, go as far as to implement strings as arrays of characters. Other programming languages may have a separate library and separate set of functions for handling common string operations, such as:
- Insert one string into another at a specified position.
- Special case: Concatenate two strings (insert a string at the beginning or the end of another).
- Special case: Append a string or a character (which may be considered a string of length one) to the end of an existing string.
- Erase a substring of a given string at a specified position with a specified length.
- Special case: erasing from the end may be faster.
- Copy: Return a substring of a given string at a specified location with a specified length.
- Find the first occurrence of a given character in a given string, or find the first occurrence of a given string as a substring of another string.
- Compare two strings lexicographically.
References[edit]
- ↑ Juha Kärkkäinen and Peter Sanders. 2003. Simple linear work suffix array construction. In Proceedings of the 30th international conference on Automata, languages and programming (ICALP'03), Jos C. M. Baeten, Jan Karel Lenstra, Joachim Parrow, and Gerhard J. Woeginger (Eds.). Springer-Verlag, Berlin, Heidelberg, 943-955. Retrieved 2010-11-13 from http://monod.uwaterloo.ca/~cs482/suffix-icalp03.pdf.