Difference between revisions of "Range minimum query"
(Created page with "The term '''range minimum query (RMQ)''' comprises all variations of the problem of finding the smallest element in a contiguous subsequence of a list of items taken from a [[tot...") |
(No difference)
|
Revision as of 05:35, 21 November 2011
The term range minimum query (RMQ) comprises all variations of the problem of finding the smallest element in a contiguous subsequence of a list of items taken from a totally ordered set (usually numbers). This is one of the most extensively-studied problems in computer science, and many algorithms are known, each of which is appropriate for a specific variation.
A single range minimum query is a set of indices 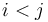 into an array
into an array 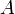 ; the answer to this query is some
; the answer to this query is some ![k \in [i,j]](/wiki/images/math/7/3/c/73ce396574257b5ac274f88d1648e7c5.png) such that
such that 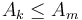 for all
for all ![m \in [i,j]](/wiki/images/math/d/e/a/dea99dc9cc2b6fce6eb32f9b13530383.png) . In isolation, this query is answered simply by scanning through the range given and selecting the minimum element, which can take up to linear time. The problem is interesting because we often desire to answer a large number of queries, so that if, for example, 500000 queries are to be performed on a single array of 10000000 elements, then using this naive approach on each query individually is probably too slow.
. In isolation, this query is answered simply by scanning through the range given and selecting the minimum element, which can take up to linear time. The problem is interesting because we often desire to answer a large number of queries, so that if, for example, 500000 queries are to be performed on a single array of 10000000 elements, then using this naive approach on each query individually is probably too slow.
Contents
Static
In the static range minimum query, the input is an array and a set of intervals (contiguous subsequences) of the array, identified by their endpoints, and for each interval we must find the smallest element contained therein. Modifications to the array are not allowed, but we must be prepared to handle queries "on the fly"; that is, we might not know all of them at once.
Sliding
This problem can be solved in linear time in the special case in which the intervals are guaranteed to be given in such an order that they are successive elements of a sliding window; that is, each interval given in input neither starts earlier nor ends later than the previous one. This is the sliding range minimum query problem; an algorithm is given in that article.
Division into blocks
In all other cases, we must consider other solutions. A simple solution for this and other related problems involves splitting the array into equally sized blocks (say, 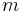 elements each) and precomputing the minimum in each block. This precomputation will take
elements each) and precomputing the minimum in each block. This precomputation will take 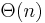 time, since it takes
time, since it takes 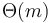 time to find the minimum in each block, and there are
time to find the minimum in each block, and there are 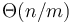 blocks.
blocks.
After this, when we are given some query ![[a,b]](/wiki/images/math/2/c/3/2c3d331bc98b44e71cb2aae9edadca7e.png) , we note that this can be written as the union of the intervals
, we note that this can be written as the union of the intervals ![[a,c_0), [c_0, c_1), [c_1, c_2), ..., [c_{k-1}, c_k), [c_k, b]](/wiki/images/math/b/9/f/b9fa16a90026f6fe46fee46bdf49bb1a.png) , where all the intervals except for the first and last are individual blocks. If we can find the minimum in each of these subintervals, the smallest of those values will be the minimum in . But because all the intervals in the middle (note that there may be zero of these if
, where all the intervals except for the first and last are individual blocks. If we can find the minimum in each of these subintervals, the smallest of those values will be the minimum in . But because all the intervals in the middle (note that there may be zero of these if 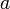 and
and 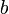 are in the same block) are blocks, their minima can simply be looked up in constant time.
are in the same block) are blocks, their minima can simply be looked up in constant time.
Observe that the intermediate intervals are 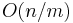 in number (because there are only about
in number (because there are only about 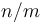 blocks in total). Furthermore, if we pick
blocks in total). Furthermore, if we pick 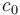 at the nearest available block boundary, and likewise with
at the nearest available block boundary, and likewise with 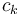 , then the intervals
, then the intervals 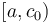 and
and ![[c_k,b]](/wiki/images/math/2/d/1/2d1a4498b3b557a8b3a75995ef2dbdf7.png) have size
have size 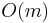 (since they do not cross block boundaries). By taking the minimum of all the precomputed block minima, and the elements in and , the answer is obtained in
(since they do not cross block boundaries). By taking the minimum of all the precomputed block minima, and the elements in and , the answer is obtained in 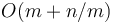 time. If we choose a block size of
time. If we choose a block size of 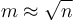 , we obtain
, we obtain 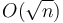 overall.
overall.
Segment tree
While is not optimal, it is certainly better than linear time, and suggests that we might be able to do better using precomputation. Instead of dividing the array into 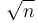 pieces, we might consider dividing it in half, and then dividing each half in half, and dividing each quarter in half, and so on. The resulting structure of intervals and subintervals is a segment tree. It uses linear space and requires linear time to construct; and once it has been built, any query can be answered in
pieces, we might consider dividing it in half, and then dividing each half in half, and dividing each quarter in half, and so on. The resulting structure of intervals and subintervals is a segment tree. It uses linear space and requires linear time to construct; and once it has been built, any query can be answered in 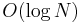 time.
time.
Sparse table
(Name due to [1].) At the expense of space and preprocessing time, we can even answer queries in 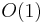 using dynamic programming. Define
using dynamic programming. Define 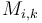 to be the minimum of the elements
to be the minimum of the elements  (or as many of those elements as actually exist); that is, the elements in an interval of size
(or as many of those elements as actually exist); that is, the elements in an interval of size 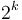 starting from
starting from 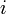 . Then, we see that
. Then, we see that 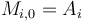 for each , and
for each , and 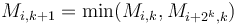 ; that is, the minimum in an interval of size
; that is, the minimum in an interval of size 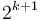 is the smaller of the minima of the two halves of which it is composed, of size . Thus, each entry of
is the smaller of the minima of the two halves of which it is composed, of size . Thus, each entry of 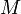 can be computed in constant time, and in total has about
can be computed in constant time, and in total has about 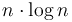 entries (since values of
entries (since values of 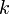 for which
for which 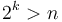 are not useful). Then, given the query , simply find such that
are not useful). Then, given the query , simply find such that 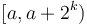 and
and ![(b-2^k,b]](/wiki/images/math/d/a/4/da44fbd7318ac69f4f94917dec7a49e3.png) overlap but are contained within ; then we already know the minima in each of these two sub-intervals, and since they cover the query interval, the smaller of the two is the overall minimum. It's not too hard to see that the desired is
overlap but are contained within ; then we already know the minima in each of these two sub-intervals, and since they cover the query interval, the smaller of the two is the overall minimum. It's not too hard to see that the desired is 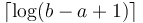 ; and then the answer is
; and then the answer is 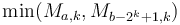 .
.
References
Much of the information in this article was drawn from a single source:
- ↑ "Range Minimum Query and Lowest Common Ancestor". (n.d.). Retrieved from http://community.topcoder.com/tc?module=Static&d1=tutorials&d2=lowestCommonAncestor#Range_Minimum_Query_%28RMQ%29