Prefix sum array and difference array
Given an array of numbers, we can construct a new array by replacing each element by the difference between itself and the previous element, except for the first element, which we simply ignore. This is called the difference array, because it contains the first differences of the original array. We will denote the difference array of array 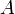 by
by 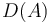 . For example, the difference array of
. For example, the difference array of ![A = [9, 2, 6, 3, 1, 5, 0, 7]](/wiki/images/math/7/f/9/7f9d88c652b184dc4db1a19714f6dd80.png) is
is ![D(A) = [2-9, 6-2, 3-6, 1-3, 5-1, 0-5, 7-0]](/wiki/images/math/e/3/5/e35ce6a5ac5351ad3daf63f72445d05b.png) , or
, or ![[-7, 4, -3, -2, 4, -5, 7]](/wiki/images/math/a/d/d/add580769fa99a870317b923383072b7.png) .
.
We see that the difference array can be computed in linear time from the original array, and is shorter than the original array by one element. Here are implementations in C and Haskell. (Note that the Haskell implementation actually takes a list, but returns an array.)
// D must have enough space for n-1 ints void difference_array(int* A, int n, int* D) { for (int i = 0; i < n-1; i++) D[i] = A[i+1] - A[i]; }
d :: [Int] -> Array Int [Int] d a = listArray (0, length a - 2) (zipWith (-) (tail a) a)
The prefix sum array is the opposite of the difference array. Given an array of numbers and an arbitrary constant 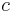 , we first append onto the front of the array, and then replace each element with the sum of itself and all the elements preceding it. For example, if we start with , and choose to append the arbitrary value
, we first append onto the front of the array, and then replace each element with the sum of itself and all the elements preceding it. For example, if we start with , and choose to append the arbitrary value 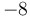 to the front, we obtain
to the front, we obtain ![P(-8, A) = [-8, -8+9, -8+9+2, -8+9+2+6, ..., -8+9+2+6+3+1+5+0+7]](/wiki/images/math/3/0/a/30a6494f688a01d72adad9f368016095.png) , or
, or ![[-8, 1, 3, 9, 12, 13, 18, 18, 25]](/wiki/images/math/5/c/c/5cc1dad3f6d3c0ccea7d7d3dd92c5bc8.png) . Computing the prefix sum array can be done in linear time as well, and the prefix sum array is longer than the original array by one element:
. Computing the prefix sum array can be done in linear time as well, and the prefix sum array is longer than the original array by one element:
// P must have enough space for n+1 ints void prefix_sum_array(int c, int* A, int n, int* P) { P[0] = c; for (int i = 0; i < n; i++) P[i+1] = P[i] + A[i]; }
p :: Int -> [Int] -> Array Int [Int] p c a = listArray (0, length a) (scanl (+) c a)
Note that every array has an infinite number of possible prefix sum arrays, since we can choose whatever value we want for . For convenience, we usually choose 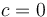 . However, changing the value of has only the effect of shifting all the elements of
. However, changing the value of has only the effect of shifting all the elements of 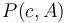 by a constant. For example,
by a constant. For example, ![P(15, A) = [15, 24, 26, 32, 35, 36, 41, 41, 48]](/wiki/images/math/2/f/5/2f55d6c3a47d61dae3b77320f34e8d9d.png) . However, each element of
. However, each element of 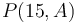 is exactly 23 more than the corresponding element from
is exactly 23 more than the corresponding element from 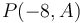 .
.
The functions 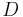 and
and 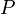 carry out reverse processes. Given an nonempty zero-indexed array :
carry out reverse processes. Given an nonempty zero-indexed array :
-
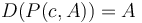 for any . For example, taking the difference array of
for any . For example, taking the difference array of ![P(-8, A) = [-8, 1, 3, 9, 12, 13, 18, 18, 25]](/wiki/images/math/0/2/b/02b6898dffbc07ad061a917cb0a015c4.png) gives
gives ![[9, 2, 6, 3, 1, 5, 0, 7]](/wiki/images/math/a/3/e/a3e4109270a19cac82c7e91bec7564e4.png) , that is, it restores the original array .
, that is, it restores the original array . -
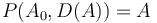 . Thus, taking
. Thus, taking ![D(A) = [-7, 4, -3, -2, 4, -5, 7]](/wiki/images/math/f/4/4/f4480db6ad3c47e96c7874fcfcea1336.png) and
and 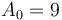 (initial element of ), we have
(initial element of ), we have ![P(A_0, D(A)) = [9, 2, 6, 3, 1, 5, 0, 7]](/wiki/images/math/9/7/a/97a41ef3e4d9b2e3dde402ac06122ea8.png) , again restoring the original array .
, again restoring the original array .
Contents
Analogy with calculus
These two processes—computing the difference array, and computing a prefix sum array—are the discrete equivalents of differentiation and integration in calculus, which operate on continuous domains. An entry in an array is like the value of a function at a particular point.
- Reverse processes:
- for any . Likewise
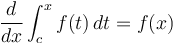 for any .
for any . - . Likewise
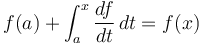 .
.
-
- Uniqueness:
- A differentiable function
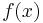 can only have one derivative,
can only have one derivative, 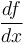 . An array can only have one difference array, .
. An array can only have one difference array, . - A continuous function has an infinite number of antiderivatives,
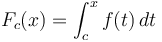 , where can be any number in its domain, but they differ only by a constant (their graphs are vertical translations of each other). An array has an infinite number of prefix arrays , but they differ only by a constant (at each entry).
, where can be any number in its domain, but they differ only by a constant (their graphs are vertical translations of each other). An array has an infinite number of prefix arrays , but they differ only by a constant (at each entry).
- A differentiable function
- Given some function
![f:[a,b]\to\mathbb{R}](/wiki/images/math/3/3/2/332d0f0f6103ad3c4ec22d3af5b36e7c.png) , and the fact that
, and the fact that 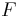 , an antiderivative of
, an antiderivative of 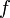 , satisfies
, satisfies 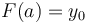 , we can uniquely reconstruct . That is, even though has an infinite number of antiderivatives, we can pin it down to one once we are given the value the antiderivative is supposed to attain on the left edge of 's domain. Likewise, given some array and the fact that , a prefix sum array of , satisfies
, we can uniquely reconstruct . That is, even though has an infinite number of antiderivatives, we can pin it down to one once we are given the value the antiderivative is supposed to attain on the left edge of 's domain. Likewise, given some array and the fact that , a prefix sum array of , satisfies 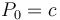 , we can uniquely reconstruct .
, we can uniquely reconstruct . - Effect on length:
- is shorter than by one element. Differentiating gives a function
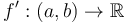 (shortens the closed interval to an open interval).
(shortens the closed interval to an open interval). - is longer than by one element. Integrating
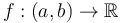 gives a function
gives a function ![F:[a,b] \to \mathbb{R}](/wiki/images/math/1/9/b/19b17cac5b2437be7e4aa88212b6ddc4.png) (lengthens the open interval to a closed interval).
(lengthens the open interval to a closed interval).
-
Because of these similarities, we will speak simply of differentiating and integrating arrays. An array can be differentiated multiple times, but eventually it will shrink to length 0. An array can be integrated any number of times.
Use of prefix sum array
The Fundamental Theorem of Calculus also has an analogue, which is why the prefix sum array is so useful. To compute an integral 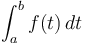 , which is like a continuous kind of sum of an infinite number of function values
, which is like a continuous kind of sum of an infinite number of function values 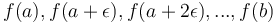 , we take any antiderivative , and compute
, we take any antiderivative , and compute  . Likewise, to compute the sum of values
. Likewise, to compute the sum of values 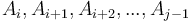 , we will take any prefix array and compute
, we will take any prefix array and compute  . Notice that just as we can use any antiderivative because the constant cancels out, we can use any prefix sum array because the initial value cancels out. (Note our use of the left half-open interval.)
. Notice that just as we can use any antiderivative because the constant cancels out, we can use any prefix sum array because the initial value cancels out. (Note our use of the left half-open interval.)
Proof: 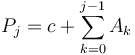 and
and 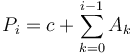 . Subtracting gives
. Subtracting gives 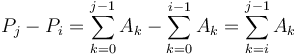 as desired.
as desired. 
This is best illustrated via example. Let as before. Take ![P(0,A) = [0, 9, 11, 17, 20, 21, 26, 26, 33]](/wiki/images/math/c/4/7/c473217b3594e5fed86c3fbef7cc3894.png) . Then, suppose we want
. Then, suppose we want 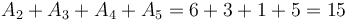 . We can compute this by taking
. We can compute this by taking 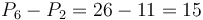 . This is because
. This is because 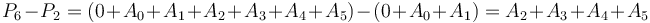 .
.
When we use the prefix sum array in this case, we generally use for convenience (although we are theoretically free to use any value we wish), and speak of the prefix sum array obtained this way as simply the prefix sum array.
Example: Counting Subsequences (SPOJ)
Computing the prefix sum array is rarely the most difficult part of a problem. Instead, the prefix sum array is kept on hand because the algorithm to solve the problem makes frequent reference to range sums.
We will consider the problem Counting Subsequences from IPSC 2006. Here we are given an array of integers 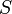 and asked to find the number of contiguous subsequences of the array that sum to 47.
and asked to find the number of contiguous subsequences of the array that sum to 47.
To solve this, we will first transform array into its prefix sum array 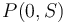 . Notice that the sum of each contiguous subsequence
. Notice that the sum of each contiguous subsequence 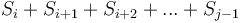 corresponds to the difference of two elements of , that is, . So what we want to find is the number of pairs
corresponds to the difference of two elements of , that is, . So what we want to find is the number of pairs 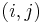 with
with 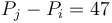 and
and 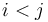 . (Note that if
. (Note that if 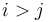 , we will instead get a subsequence with sum -47.)
, we will instead get a subsequence with sum -47.)
However, this is quite easy to do. We sweep through from left to right, keeping a map of all elements of we've seen so far, along with their frequencies; and for each element 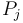 we count the number of times
we count the number of times  has appeared so far, by looking up that value in our map; this tells us how many contiguous subsequences ending at
has appeared so far, by looking up that value in our map; this tells us how many contiguous subsequences ending at 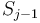 have sum 47. And finally, adding the number of contiguous subsequences with sum 47 ending at each entry of gives the total number of such subsequences in the array. Total time taken is
have sum 47. And finally, adding the number of contiguous subsequences with sum 47 ending at each entry of gives the total number of such subsequences in the array. Total time taken is 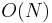 , if we use a hash table implementation of the map.
, if we use a hash table implementation of the map.
Use of difference array
The difference array is used to keep track of an array when ranges of said array can be updated all at once. If we have array and add an increment 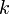 to elements
to elements 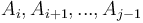 , then notice that
, then notice that 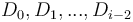 are not affected; that
are not affected; that 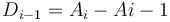 is increased by ; that
is increased by ; that 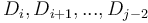 are not affected; that
are not affected; that 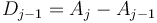 is decreased by ; and that
is decreased by ; and that 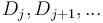 are unaffected. Thus, if we are required to update many ranges of an array in this manner, we should keep track of rather than itself, and then integrate at the end to reconstruct .
are unaffected. Thus, if we are required to update many ranges of an array in this manner, we should keep track of rather than itself, and then integrate at the end to reconstruct .
Example: Wireless (CCC)
This is the basis of the model solution to Wireless from CCC 2009. We are given a grid of lattice points with up to 30000 rows and up to 1000 columns, and up to 1000 circles, each of which is centered at a lattice point. Each circle has a particular weight associated with it. We want to stand at a lattice point such that the sum of the weights of all the circles covering it is maximized, and to determine how many such lattice points there are.
The most straightforward way to do this is by actually computing the sum of weights of all covering circles at each individual lattice point. However, doing this naively would take up to 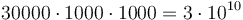 operations, as we would have to consider each lattice point and each circle and decide whether that circle covers that lattice point.
operations, as we would have to consider each lattice point and each circle and decide whether that circle covers that lattice point.
To solve this, we will treat each column of the lattice as an array , where entry 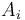 denotes the sum of weights of all the circles covering the point in row
denotes the sum of weights of all the circles covering the point in row 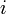 of that column. Now, consider any of the given circles. Either this circle does not cover any points in this column at all, or the points it covers in this column will all be consecutive. (This is equivalent to saying that the intersection of a circle with a line is a line segment.) For example, a circle centered at
of that column. Now, consider any of the given circles. Either this circle does not cover any points in this column at all, or the points it covers in this column will all be consecutive. (This is equivalent to saying that the intersection of a circle with a line is a line segment.) For example, a circle centered at 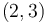 with radius
with radius 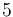 will cover no lattice points with x-coordinate
will cover no lattice points with x-coordinate 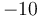 , and as for lattice points with x-coordinate
, and as for lattice points with x-coordinate 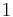 , it will cover
, it will cover 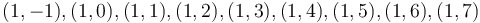 . Thus, the circle covers some first point and some last point
. Thus, the circle covers some first point and some last point 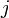 , and adds some value
, and adds some value 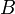 to each point that it covers; that is, it adds to
to each point that it covers; that is, it adds to 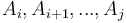 . Thus, we will simply maintain the difference array , noting that the circle adds to
. Thus, we will simply maintain the difference array , noting that the circle adds to 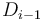 and takes away from
and takes away from 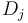 . We maintain such a difference array for each column; and we perform at most two updates for each circle-column pair; so the total number of updates is bounded by
. We maintain such a difference array for each column; and we perform at most two updates for each circle-column pair; so the total number of updates is bounded by 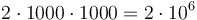 . (The detail of how to keep track of the initial element of is left as an exercise to the reader.) After this, we perform integration on each column and find the maximum values, which requires at most a constant times the total number of lattice points, which is up to
. (The detail of how to keep track of the initial element of is left as an exercise to the reader.) After this, we perform integration on each column and find the maximum values, which requires at most a constant times the total number of lattice points, which is up to 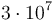 .
.
Multiple dimensions
The prefix sum array and difference array can be extended to multiple dimensions.
Prefix sum array
We start by considering the two-dimensional case. Given an 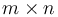 array , we will define the prefix sum array
array , we will define the prefix sum array 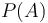 as follows:
as follows: 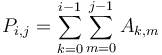 . In other words, the first row of is all zeroes, the first column of is all zeroes, and all other elements of are obtained by adding up some upper-left rectangle of values of . For example,
. In other words, the first row of is all zeroes, the first column of is all zeroes, and all other elements of are obtained by adding up some upper-left rectangle of values of . For example, 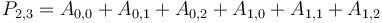 . Or, more easily expressed,
. Or, more easily expressed, 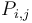 is the sum of all entries of with indices in
is the sum of all entries of with indices in 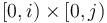 (Cartesian product).
(Cartesian product).
In general, if we are given an 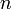 -dimensional array with dimensions
-dimensional array with dimensions 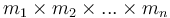 , then the prefix sum array has dimensions
, then the prefix sum array has dimensions 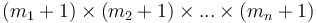 , and is defined by
, and is defined by 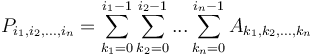 ; or we can simply say that it is the sum of all entries of with indices in
; or we can simply say that it is the sum of all entries of with indices in 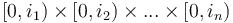 .
.
To compute the prefix sum array in the two-dimensional case, we will scan first down and then right, as suggested by the following C++ implementation:
vector<vector<int> > P(vector<vector<int> > A) { int m = A.size(); int n = A[0].size(); // Make an m+1 by n+1 array and initialize it with zeroes. vector<vector<int> > p(m+1, vector<int>(n+1, 0)); for (int i = 1; i <= m; i++) for (int j = 1; j <= n; j++) p[i][j] = p[i-1][j] + A[i-1][j-1]; for (int i = 1; i <= m; i++) for (int j = 1; j <= n; j++) p[i][j] += p[i][j-1]; return p; }
Here, we first make each column of the prefix sum array of a column of , then convert each row of into its prefix sum array to obtain the final values. That is, after the first pair of for loops, will be equal to 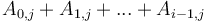 , and after the second pair, we will then have
, and after the second pair, we will then have 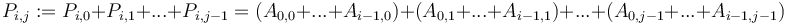 , as desired. The extension of this to more than two dimensions is straightforward.
, as desired. The extension of this to more than two dimensions is straightforward.
(Haskell code is not shown, because using functional programming in this case does not make the code nicer.)
After the prefix sum array has been computed, we can use it to add together any rectangle in , that is, all the elements with their indices in 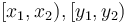 . To do so, we first observe that
. To do so, we first observe that  gives the sum of all the elements with indices in the box
gives the sum of all the elements with indices in the box 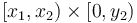 . Then we similarly observe that
. Then we similarly observe that  corresponds to the box
corresponds to the box 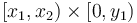 . Subtracting gives the box
. Subtracting gives the box  . This gives a final formula of
. This gives a final formula of  .
.
In the -dimensional case, to sum the elements of with indices in the box 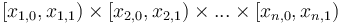 , we will use the formula
, we will use the formula 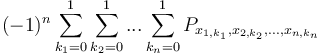 . We will not state the proof, instead noting that it is a form of the inclusion–exclusion principle.
. We will not state the proof, instead noting that it is a form of the inclusion–exclusion principle.
Example: Diamonds (BOI)
The problem Diamonds from BOI '09 is a straightforward application of the prefix sum array in three dimensions. We read in a three-dimensional array , and then compute its prefix sum array; after doing this, we will be able to determine the sum of any box of the array with indices in the box 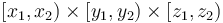 as
as 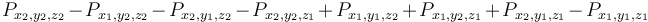 .
.
Difference array
To use the difference array properly in two dimensions, it is easiest to use a source array with the property that the first row and first column consist entirely of zeroes. (In multiple dimensions, we will want 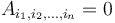 whenever any of the 's are zero.)
whenever any of the 's are zero.)
We will simply define the difference array to be the array whose prefix sum array is . This means in particular that 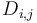 is the sum of elements of with indices in the box
is the sum of elements of with indices in the box  (this box contains only the single element ). Using the prefix sum array , we obtain
(this box contains only the single element ). Using the prefix sum array , we obtain 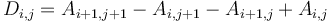 . In general:
. In general:
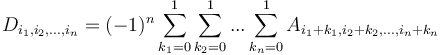 .
.
Should we actually need to compute the difference array, on the other hand, the easiest way to do so is by reversing the computation of the prefix sum array:
vector<vector<int> > D(vector<vector<int> > A) { int m = A.size(); int n = A[0].size(); // Make an m+1 by n+1 array vector<vector<int> > d(m-1, vector<int>(n-1)); for (int i = 0; i < m-1; i++) for (int j = 0; j < n-1; j++) d[i][j] = A[i+1][j+1] - A[i+1][j]; for (int i = m-2; i > 0; i--) for (int j = 0; j < n-1; j++) d[i][j] -= d[i-1][j]; return d; }
In this code, we first make each column of the difference array of the corresponding column of , and then treat each row as now being the prefix sum array of the final result (the row of the difference array), so we scan backward through it to reconstruct the original array (i.e., take the difference array of the row). (We have to do this backward so that we won't overwrite a value we still need later.) The extension to multiple dimensions is straightforward; we simply have to walk backward over every additional dimension as well.
Now we consider what happens when all elements of with coordinates in the box given by 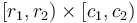 are incremented by . If we take the difference array of each column of now, as in the function
are incremented by . If we take the difference array of each column of now, as in the function D defined above, we see that for each column, we will have to add to entry 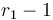 and subtract it from
and subtract it from 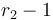 (as in the one-dimensional case). Now if we take the difference array of each row of what we've just obtained, we notice that in row number , we've added to every element in columns in
(as in the one-dimensional case). Now if we take the difference array of each row of what we've just obtained, we notice that in row number , we've added to every element in columns in 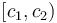 in the previous step, and in row number , we've subtracted to every element in the same column range, so in the end the effect is to add to elements
in the previous step, and in row number , we've subtracted to every element in the same column range, so in the end the effect is to add to elements 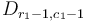 and
and 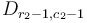 , and to subtract from elements
, and to subtract from elements 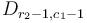 and
and 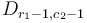 .
.
In the general case, when adding to all elements of with indices in the box , a total of 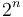 elements of need to be updated. In particular, element
elements of need to be updated. In particular, element 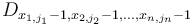 (where each of the 's can be either 0 or 1, giving possibilities in total) is incremented by
(where each of the 's can be either 0 or 1, giving possibilities in total) is incremented by 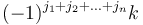 . That is, if we consider an -dimensional array to be an -dimensional hypercube of numbers, then the elements to be updated lie on the corners of an -dimensional hypercube; we 2-color the vertices black and white (meaning two adjacent vertices always have opposite colours), with the lowest corner (corresponding to indices
. That is, if we consider an -dimensional array to be an -dimensional hypercube of numbers, then the elements to be updated lie on the corners of an -dimensional hypercube; we 2-color the vertices black and white (meaning two adjacent vertices always have opposite colours), with the lowest corner (corresponding to indices ![[x_{1,0}-1, x_{2,0}-1, ..., x_{n,0}-1]](/wiki/images/math/e/e/9/ee969b6f137475e7cbacf3b7c020acbb.png) ) white; and each white vertex receiving
) white; and each white vertex receiving 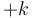 and each black vertex
and each black vertex 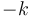 . One can attempt to visualize the effect this has on the prefix sum array in three dimensions, and become convinced that it makes sense in dimensions. Each element in the prefix sum array
. One can attempt to visualize the effect this has on the prefix sum array in three dimensions, and become convinced that it makes sense in dimensions. Each element in the prefix sum array 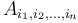 is the sum of all the elements in some box of the difference array with its lowest corner at the origin, . If the highest corner actually lies within the hypercube, that is,
is the sum of all the elements in some box of the difference array with its lowest corner at the origin, . If the highest corner actually lies within the hypercube, that is, 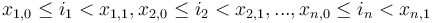 , then this box is only going to contain the low corner
, then this box is only going to contain the low corner 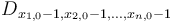 , which has increased by ; thus, this entry in has increased by as well, and this is true of all elements that lie within the hypercube,
, which has increased by ; thus, this entry in has increased by as well, and this is true of all elements that lie within the hypercube, ![[x_{1,0},x_{1,1}) \times [x_{2,0},x_{2,1}) \times ... \times [x_{n,0},x_{n,1}]](/wiki/images/math/0/d/7/0d7770ae76d985eefec202c62a1e5164.png) . If any of the 's are less than the lower bound of the corresponding
. If any of the 's are less than the lower bound of the corresponding 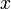 , then our box doesn't hit any of the vertices of the hypercube at all, so all these elements are unaffected; and if instead any one of them goes over the upper bound, then our box passes in through one hyperface and out through another, which means that corresponding vertices on the low and high face will either both be hit or both not be hit, and each pair cancels itself out, giving again no change outside the hypercube.
, then our box doesn't hit any of the vertices of the hypercube at all, so all these elements are unaffected; and if instead any one of them goes over the upper bound, then our box passes in through one hyperface and out through another, which means that corresponding vertices on the low and high face will either both be hit or both not be hit, and each pair cancels itself out, giving again no change outside the hypercube.
Example: The Cake is a Dessert
The Cake is a Dessert from the Woburn–Waterloo 2011 Mock CCC is a straightforward application of the difference array in two dimensions.