Judge:Writing
This page documents current best practices for writing problems and analyses on the PEG Judge.
Contents
Problem statements
As a rule, problem statements, written in HTML, should adhere to the PEG Judge Standard Format, in order to give them a consistent look and feel that can also be consistently modified by CSS should the PEG Judge later introduce multiple skins for its interface. This is specified in the sections to follow.
General guidelines
The document should be valid XHTML 1.0 Transitional. This means, among other things:
- No non-ASCII characters should appear directly in the source; they must appear as HTML entities. Watch out for fancy quotation marks, in particular; these are unwelcome. Use the standard apostrophes (') and ASCII double quotes (") instead.
- Tags should not overlap.
- All tags should be closed. <p> tags, in particular, must be closed. It is true that browsers can render pages correctly even when they are not closed, but it's bad practice not to close them.
- All images should have alt-text, even if it is blank.
- Use scientific notation rather than long strings of zeroes; for example, 2×109 instead of 2000000000. Do not use commas (as in 2,000,000,000) or metric spacing (as in 2 000 000 000).
- Do not link to external images. Link to images that are stored on the PEG Judge server in the
imagesdirectory. (Don't worry about the absolute path; this is taken care of using some server-side magic.) - Use LaTeX, if you think it will be helpful. See here.
The sections listed below should occur in the order listed.
Heading
The title of the problem should be a second-level header (<h2>) found at the top of the document.
Unless the PEG Judge is the place where this particular problem originally appeared, the source of the problem should be a third-level header (<h3>) that immediately precedes the title (such as "2003 Canadian Computing Competition, Stage 1").
Body
The problem statement body should immediately follow the title, with no heading.
- Lines should be kept to a maximum of 80 characters when it is reasonably practical, as is standard practice in coding.
- Variables should be enclosed in <var> tags, rather than the less semantically meaningful <i> tag, or the semantically misleading <em> tag.
- No bounds should appear in the body.
- <p> tags should always be used for paragraphing, instead of manually inserted <br/>. However, this does not mean that using line breaks is disallowed.
Input
Immediately following the problem statement body should be the input section, headed by <h3>Input</h3>. This section should describe the input format clearly and unambiguously. It should refer to variables given in input by the same names that are used in the problem description body, and it should mention them in the order in which they appear in the input file. It should state the type and bounds of each variable as it is given, in a format that conforms closely to this example:
An integer <var>T</var> (1 ≤ <var>T</var> ≤ 100), indicating the number of lines to follow.
The features of this example that should be imitated in problem statements are as follows:
- The variable is enclosed in <var> tags.
- The less-than-or-equal-to operator character appears as its HTML entity (not as the character itself) in the source.
- The qualifier "integer" appears, to let the reader know that T is not a floating-point number or a string.
- The bounds are given in parentheses, immediately after the mention of the variable itself. The non-breaking space character is used to prevent the expression in the parentheses from being broken across lines.
If any input data are strings, the input section should specify exactly which characters are allowed to appear in said strings.
Output
Immediately following the input section should be the output section, headed by <h3>Output</h3>. This section should describe the output format clearly and unambiguously. In particular:
- If there can be multiple possible solutions to input test cases, it should either specify that any solution should be accepted, or that all solutions should be produced. In the latter case it should specify whether they are to be output in a specific order, or whether any order will be accepted.
- If there can, in general, be multiple possible solutions to possible test inputs, but the actual test inputs are chosen in such a way that there will a unique solution to each one, then this fact should be indicated.
- If any output is a floating-point number, the output section should specify the acceptable absolute and/or relative margins of error; or it should specify that the output is to be given to a certain number of decimal places.
- It is implied that the rounding convention is round-to-even. If output is expected to adhere to a different rounding convention (such as ↓4/5↑ or round-to-zero a.k.a. truncate), this should be clearly indicated.
Sample data
The output section should be immediately followed by sample data. Sample data should always be given in a fixed-width font; it is strongly recommended that you use the <pre> tag. There is, however, some flexibility in organization:
- If there is only one sample test case, it's usually best to have a Sample Input section (headed by <h3>Sample Input</h3>), containing the sample input, followed by a Sample Output section (headed by <h3>Sample Output</h3>), containing the sample output.
- If there are multiple test cases, one option is to have multiple pairs of sections (hence, Sample Input 1, Sample Output 1, Sample Output 2, Sample Output 2, and so on); another is to have a single section "Sample Cases" with a table that organizes the input-output pairs in a nice way.
Grading
If the possibility of earning partial credit exists for your problem, you should include a section about grading, headed by <h3>Grading</h3>, to give extra information about how partial credit may be earned on a test case (typically by outputting valid but suboptimal output) along with a precise specification of the formula used to calculate partial credit.
At your liberty, you may also explain how partial credit may be earned on the problem as a whole; typically, by stating some guarantees about the score that can be obtained by solving small test cases with suboptimal algorithms (e.g., "Test cases that contain no more than 300 lines of input each will make up at least 30% of the points for this problem.") If you are copying the problem from a source such as the IOI that gives such partial credit information, you should also copy such partial credit information into this section.
This is also the section where additional information about, e.g., interactivity should go. For example, a reminder to the reader to flush the standard output stream after each newline.
Analyses
Analyses should adhere to all the general guidelines for problem statements. You are also encouraged to include a byline that includes either your real name or your PEG Judge handle (or both). The format is otherwise flexible.
Unless the problem is very open-ended, the analysis should discuss the algorithmic and/or implementational techniques required to write a parsimonious solution that will achieve a full score on the problem ("model solution"), preferably with a source link to an implementation of said solution, preferably written in an IOI language (C, C++, or Pascal). It should similarly discuss any sub-optimal solutions hinted to in the "Grading" section of the problem statement (that is, simpler solutions that still achieve reasonable scores). Alternative solutions that can also earn full marks may also be discussed.
The algorithmic aspect of the solution explanation should give a complete high-level overview. Because the analysis will only be viewed by users who have solved the problem, it should be aimed at such an audience and should not burden the reader with details that will seem obvious. It should outline exactly enough details so that the reader will be able to implement the model solution after reading and understanding the analysis. For example, it should identify key data structures and basic well-known algorithms, but should avoid delving into their details unless they are novel. (The reader should be expected to be familiar with, e.g, binary indexed trees and Dijkstra's algorithm.) It should analyze the asymptotic time and space complexity of the solutions presented.
The implementational aspect can often be omitted, but should be included if simple implementations of the model algorithm may fail to earn full marks from want of constant optimization.
If you wish, you can also discuss the nature of the actual test data, heuristics that would work well or have been found to work well for those particular inputs, and tricky cases.
LaTeX
You can include mathematical formulae directly on analyses, just as you can include them on this wiki. For example,
<latex>$x = \frac{-b \pm \sqrt{b^2-4ac}}{2a}$</latex>
gives something similar to 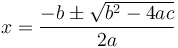 .
.
Specifically, the string enclosed in the tags is inserted into the template:
\documentclass[11pt]{article} \usepackage[paperwidth=8.5in, paperheight=100in]{geometry} \usepackage{amsmath} \usepackage{amssymb} \pagestyle{empty} \begin{document} % your code goes here \end{document}
which is then compiled and converted. The final result is an <img> link to the rendered LaTeX, stored on the server.
This works on problem descriptions, too (but not in comments).
Test data
Input data should be rigorously formatted. The admins will be very angry if the test data causes inconvenience to users by breaking any of the following rules:
- It should consist only of printable ASCII characters and newlines. It should not contain other control characters (not even tabs), nor should it contain any non-ASCII characters, such as letters with accents, or fancy quotation marks, or dashes, or box-drawing characters, or...
- In particular, because the PEG Judge runs Linux, text files should be in UNIX format: line-ending sequence must be the line feed character (0x0A, a.k.a., "\n") alone, without any accompanying carriage return character (0x0D, a.k.a. "\r") as in Windows. This is important because the reader should be entitled to the assumption that newlines will be in UNIX format, which may cause their programs to misbehave if certain input methods are used that can actually pick up carriage returns separately from line feeds (such as
getchar()), as opposed to, e.g.,scanf(), to which the difference is transparent.
- In particular, because the PEG Judge runs Linux, text files should be in UNIX format: line-ending sequence must be the line feed character (0x0A, a.k.a., "\n") alone, without any accompanying carriage return character (0x0D, a.k.a. "\r") as in Windows. This is important because the reader should be entitled to the assumption that newlines will be in UNIX format, which may cause their programs to misbehave if certain input methods are used that can actually pick up carriage returns separately from line feeds (such as
- If any strings containing spaces are to be given in input, each such string must occur on a separate line; no other input data may be given on the same line. For example, an input line that consists of an integer followed by a space followed by a string that may contain spaces is unacceptable.
- If parts of the input data consist of individual characters (e.g., "The next line of input will contain a single character..."), do not allow those characters to be spaces unless there is a really good reason why you need to be able to give space characters in input. If you absolutely must include characters that may be spaces, each such character must occur on a separate line, with no other input data given on that line.
- In all other cases, a line must not start with a space, end with a space, or have two or more spaces in a row. It should consist of zero or more items, each of which should be an integer, a floating-point number, a character (that is not a space), or a string (that contains no spaces); items should be separated by single spaces, unless there is some good reason to use a different separator (such as giving the score of a sporting event in a format like "2-0").
- A number may start with at most one sign symbol, either "+" or "-".
- An integer must not start with zero, unless the integer is 0 itself. It must be given as an unbroken sequence of digits. It may not contain any spaces, periods, or commas, and it may not be expressed in scientific notation.
- The integer part of a floating-point number must not start with zero, unless it is 0 itself. It must be given as an unbroken sequence of digits, followed by an optional decimal point (which must be a period, rather than a comma), followed by another unbroken sequence of digits. Commas and spaces must not appear. Scientific notation may not be used. The decimal point is allowed to appear at the end (e.g., "2.") but not at the beginning (e.g., ".2"; use "0.2" instead).
- The last datum must be followed by a single newline character; put another way, the last line of the input file must be blank. Furthermore, blank lines, other than the blank line at the very end, are allowed to appear only when they represent the empty string. For example, a test file that consists only of numbers is not allowed to contain any blank lines, except the one at the very end.
- Unless there is a very good reason to do so, do not design the input format in such a way that the end of input can be detected only as the end of file. If you must include multiple test cases in one file, specify the number of test cases at the very beginning of the file, so that the program will know when to stop reading.
Do not require output to contain any of the forbidden characters either (ASCII control characters other than the space and newline, or non-ASCII characters), unless there is a very good reason to do so (see Pipe Dream). In the case that you wish to use non-ASCII characters, remember that the PEG Judge uses UTF-8 encoding everywhere.