String searching
The string searching or string matching problem is that of locating one string, known as a needle or a pattern, as a substring of another, longer string, known as a haystack or the text. (These terms are derived from the idiom finding a needle in a haystack.) It is precisely the function implemented by the "Find" feature in a text editor or web browser. Because of the information explosion and the fact that much of the information in the world exists in the form of text, efficient information retrieval by means of string searching is instrumental in a wide variety of applications. Consequently, this problem is one of the most extensively studied in computer science. The more general problem of determining whether a text contains a substring of a particular form, such as a regular expression, is known as pattern matching.
Discussion
In theory, the string searching problem could be formulated as a decision problem, the problem of whether or not the needle is a substring of the haystack. However, this variation is often not used in practice, since we almost always want to know where the needle occurs in the haystack, and none of the important string searching algorithms make it difficult to determine this once they have established that the substring exists. (For example, the string mat appears twice in mathematics, once starting from the first character, and once starting from the sixth character.) On the other hand, sometimes we will only care about the first or the last position at which the needle occurs in the haystack, and other times we will want to find all positions at which it matches.
If a string searching algorithm is to be used on only one needle-haystack pair, its efficiency is determined by two factors: the length of the needle, 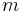 , and the length of the haystack,
, and the length of the haystack, 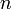 . Several algorithms achieve the asymptotically optimal
. Several algorithms achieve the asymptotically optimal 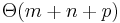 worst-case runtime here (where
worst-case runtime here (where 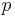 is the number of matches found for the needle in the haystack), which is linear time.
is the number of matches found for the needle in the haystack), which is linear time.
We will sometimes want to search for one needle in multiple texts; the "Search" feature of your operating system, for example, will accept one search string and attempt to locate it in multiple files. Using any single-pattern, single-text linear-time string searching algorithm for this case will also give an asymptotically optimal linear-time algorithm, as it will use 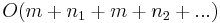 time, which is the same as
time, which is the same as 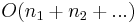 since the needle is never longer than the haystack (and hence the sum of the needle and haystack lengths is never more than twice the haystack length). That is, preprocessing the needle will not give a multiple-text string searching algorithm that is asymptotically faster than running an asymptotically optimal single-pattern, single-text algorithm once on each text.
since the needle is never longer than the haystack (and hence the sum of the needle and haystack lengths is never more than twice the haystack length). That is, preprocessing the needle will not give a multiple-text string searching algorithm that is asymptotically faster than running an asymptotically optimal single-pattern, single-text algorithm once on each text.
The situation is very different when we want to search for multiple needles in one text. As an example, a biologist may frequently wish to locate genes in the human genome. This 3.3 billion-character text produced through the efforts of the Human Genome Project does not change, but the there are undoubtedly a great number of different genes (patterns) that biologists may wish to locate in it. Here, if we run a single-pattern, single-text algorithm for each pattern, we have to consider the entire text each time. When the text is much longer than the patterns, the behavior of this strategy is much worse than linear time. It is possible to preprocess the text so that it will not be necessary to iterate through the entire text each time a new pattern is searched for within it. This is known as indexing.